好久没有更新博客了,由于工作内容的调整,所负责的服务更多需要面向用户侧网络来推进,由于公网链路的复杂性,各种奇怪的网络问题也陆续接触到,抽空把最近工作中碰到的一些关于mtu的问题来做个小的知识总结。
什么是MTU
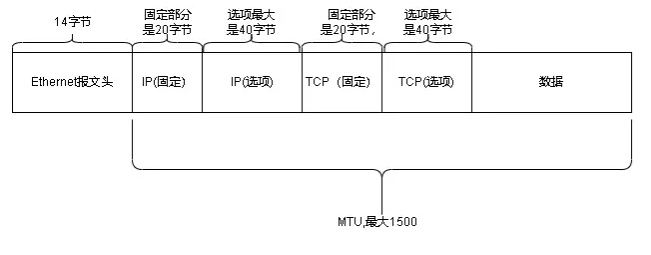
对于网络传输来说,提升数据收发效率一个关键的点就是尽量在双端网络链路允许的情况下提升每一次传输实际payload数据的发送量,那么限制每次网络传输的关键技术指标就是MTU(Maximum Transmission Unit)。在7层网络协议中,MTU是数据链路层的概念,MTU限制的是数据链路层的payload,也就是上层协议的大小(例如:IP包、ICMP包的大小)。
标准以太网(Ethernet II)数据帧大小是1518,头信息有14字节,尾部校验和FCS占4字节,所以标准以太网数据帧实际能携带的最大的payload大小就是:1518 - 14 - 4 = 1500。
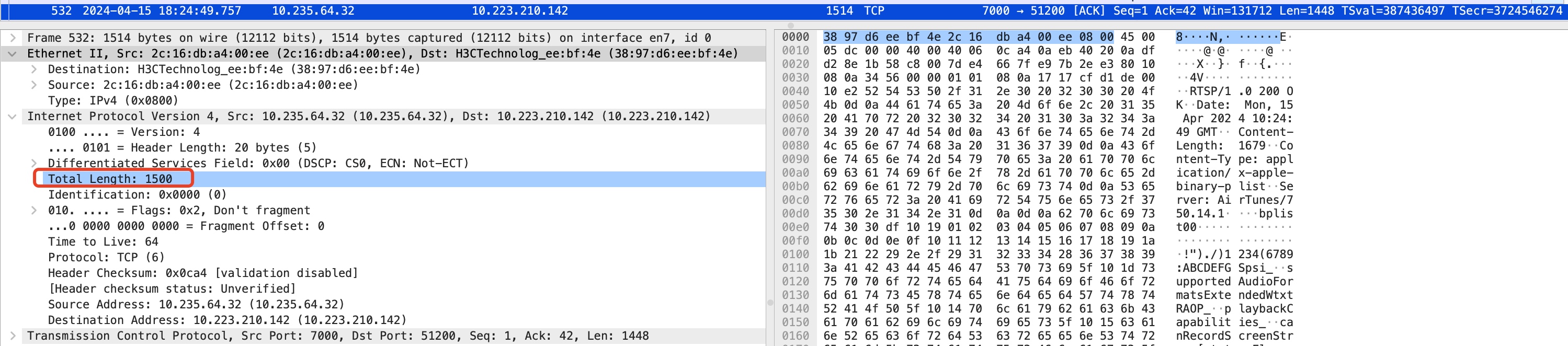 以太网数据帧考虑大小限制在1518主要是考虑一次传输延迟和传输效率的折中。
100Mbps带宽下传输时间:
( 1518 * 8 ) / ( 100 * 1024 * 1024 ) * 1000 = 0.11(ms)
2Mbps传输时间:
( 1518 * 8 ) / ( 2 * 1024 * 1024 ) * 1000 = 5.79(ms)
以太网数据帧考虑大小限制在1518主要是考虑一次传输延迟和传输效率的折中。
100Mbps带宽下传输时间:
( 1518 * 8 ) / ( 100 * 1024 * 1024 ) * 1000 = 0.11(ms)
2Mbps传输时间:
( 1518 * 8 ) / ( 2 * 1024 * 1024 ) * 1000 = 5.79(ms)
如果传输路径的MTU不准确会发生什么
以IPv4为例,IP数据包的最大长度是64K字节(65535),因为在IP包头中用2个字节描述报文长度,2个字节所能表达的最大数字就是65535。然而网络中有多种不同的传输链路,每种链路的MTU都不一样。
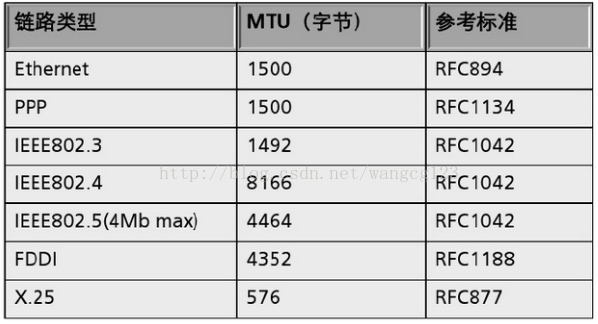
对于传输路径中的MTU如果不准确,可能会存在两种情况。
- 第一种:IP包在发出时未设置DF(Dont Fragment)标志位,那么在发出后,如果链路中出现MTU比当前IP包更小的情况,那么会在该环节进行IP包分片。比如一台router从FDDI接口收到了一个大小为4352 bytes 的数据包,为了从Ethernet接口把该数据发送出去就需要在路由器进行IP包分片,将一个大的数据包切分为多个小的数据包从而满足 Ethernet 1500 bytes MTU 的要求。除了不同的传输链路的MTU不一样导致需要进行IP分片外,同一种传输链路中也可能存在MTU不一致的情况,比如以太网链路中有路由器MTU设置较小,也会导致收发双端的数据包在路由器被分片。

对于这种在链路中被分片的情况实际上是并不被鼓励的,原因有以下几点:
- 需要占用更多的 CPU 和 RAM 来进行 fragmentation 和 reassembling。Router 的 RAM 有限,进行 reassembling 的时候需要把未接收完的数据包都放在 buffer 里面排队,对系统的影响较大。
- 如果被 fragment 的数据包在传输中出现任意一个掉包那么全部的数据都需要进行重传,例如 1 个大的数据包被分为了 6 个小的数据包进行传输,那么任何一个小数据包掉包都会导致重传 6 个数据包。
- 一个大的数据包进行 fragmentation 后会变为 initial fragment (第一个数据包)和 non-initial fragment (第二个及以后的数据包),non-initial fragment 数据包只带有 3 层信息。如果数据在传输的过程中出现了 out of order,有些防火墙如果收到的第一个数据包是 non-initial fragment 就会将其丢弃。non-initial fragment 可以穿透一些未配置正确的防火墙或者 ACL 从而实现 IP fragmentation attack。
- 第二种:IP包在发出时有明确设置DF(Dont Fragment)标志位,那么在发出后,如果链路中出现MTU比当前IP包更小的情况,中间链路设备不能针对该IP包进行分片,同时也由于MTU限制也不能继续往下转发,所以只能终止发送,并回一个ICMP包(code为4 Fragmentation needed but no frag. bit set)给发送方,并明确告知当前中间设备的MTU值。 PS: 对于IPv4协议来说,如果net.ipv4.ip_no_pmtu_disc设置为0开启,那么所有发出的IP报文默认都会设置DF标志位,如果net.ipv4.ip_no_pmtu_disc没有开启,那么需要在创建socket的时候指定DF选项。
如何避免IP分片
既然要避免在网络(IP)层的自动分片,那就需要在应用层数据提交到网络(IP)层之前就把数据提前进行分片,同时接收到被分片的同一组的多个IP包后,也需要重新组装合并成应用层需要的数据。比如TCP协议在建联的时候会协商MSS,协商的目的是知道对方的MTU是多少,以便在协议栈层针对交给网络(IP)层的数据进行提前分片。 一个好的消息是:对于IPv6来说,不再支持中间节点分片,仅支持端到端的分片。中间链路的路由器设备不再check分片相关的字段,也不用再处理分片和重组的逻辑,IP层的整体效率是有提升的。但同时也意味着IPv6下对于路径的MTU探测需要更准确(因为只要中间链路的MTU比当前发出的IP更小,这个IP包就一定会被丢弃),因此为了避免MTU探测不准确可能带来的风险,IPv6规范规定MTU的最小支持大小为1280字节,这样即使探测存在问题,基本上1280的大小也能覆盖绝大部分场景。
IP层的PMTUD
那么接下来看一下IP层PMTUD。对于确定两个IP主机之间的Path MTU,RFC 1191(IPv4)和RFC 1981(IPv6)定义了动态探测PMTU的技术-PMTUD(Path MTU Discovery)。首先源节点假设Path MTU就是其出接口的MTU,发出一个试探性的报文,并设置该报文不允许被分片。当转发路径上存在一个小于当前假设的Path MTU时,转发设备就会向源节点发送回应的 ICMP 报文,并且携带自己的MTU值,此后源节点将Path MTU的假设值更改为新收到的MTU值继续发送报文。如此反复,直到报文到达目的地之后,源节点就能知道到达目的地的Path MTU了。 系统通过以下参数来控制:
net.ipv4.ip_no_pmtu_disc
0: 开启 MTU 发现(默认值),如果接收到code 4的ICMP报文,则会将路径上的PMTU设置成ICMP返回的MTU值;
1:,代表关闭,此时如果接收到code 4的ICMP报文,则会将路径上的PMTU直接设置成min_pmtu,不会参考ICMP返回的MTU值;
2: 接收到的路径 MTU 发现消息会被丢弃,发送帧的处理同模式 1;
3: 为强化的PMTU发现模式;
net.ipv4.route.min_pmtu
最小的路径 MTU,默认为 522
对于开启了net.ipv4.ip_no_pmtu_disc的场景,在接收到code为4的ICMP包后,会针对该IP调整MTU:
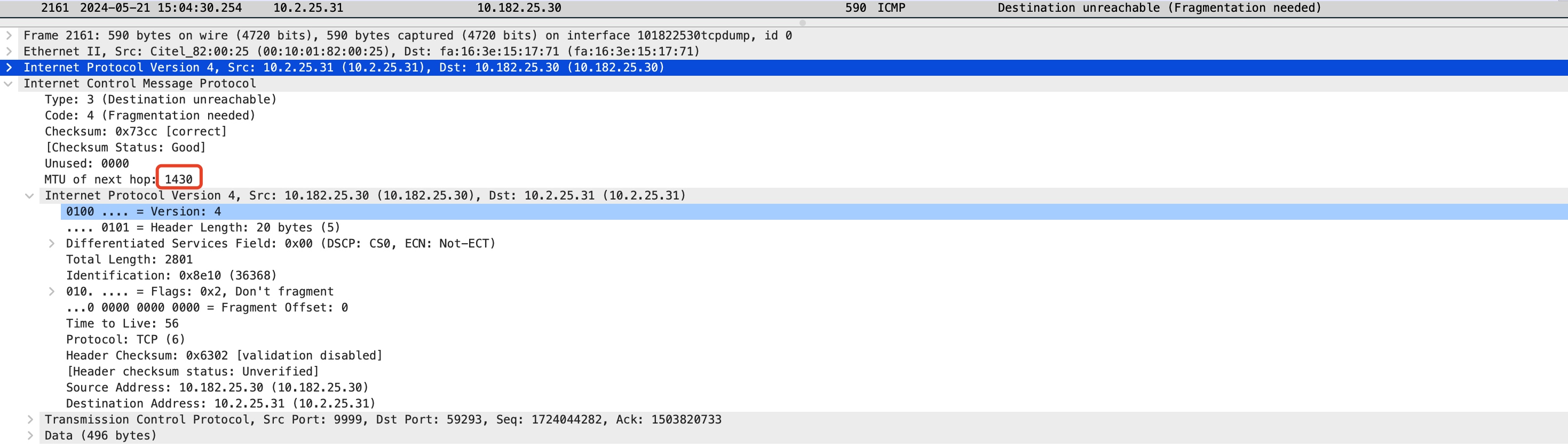
sudo ip route show cache
10.2.25.31 via 10.182.25.1 dev eth0
cache expires 286sec mtu 1430
如上是net.ipv4.ip_no_pmtu_disc设置为0(开启)时,在接收到ICMP包后,会将本机到对端IP的MTU设置为ICMP包中上报的1430。
ICMP black hole
虽然IP层有对PMTU的探测机制,但是有些时候这个机制并不能发挥作用,其中一个主要原因是发送端由于回程链路某一个环节的问题无法收到ICMP包,比如一个典型的场景:如果回给内网服务器的ICMP包回程链路会经过四层DPVS,由于DPVS会丢弃所有ICMP包,所以导致后面的服务器无法触发PMTUD的后续调整策略。至于为啥DPVS会丢弃ICMP包,实际上也并不是完全没道理,因为FullNAT模式下后端服务器看到的客户端源IP都是DPVS自身的IP,如果ICMP包透传给后端服务器,那么服务器端基于IP维度的MTU最终只能记录成DPVS自身IP的,而不是基于客户端真实源IP,这样实际上得到的MTU也是不准确的。所以DPVS干脆就都丢弃了,迫使后端服务器在更高层维度(比如传输层或者应用层)来做MTU探测。
TCP协议的MTU探测
针对ICMP黑洞导致PMTUD无法生效的问题,可以在IP层之上的传输层来进行传输层、应用层的提前切片协商或者上层的MTU探测。
MSS通告
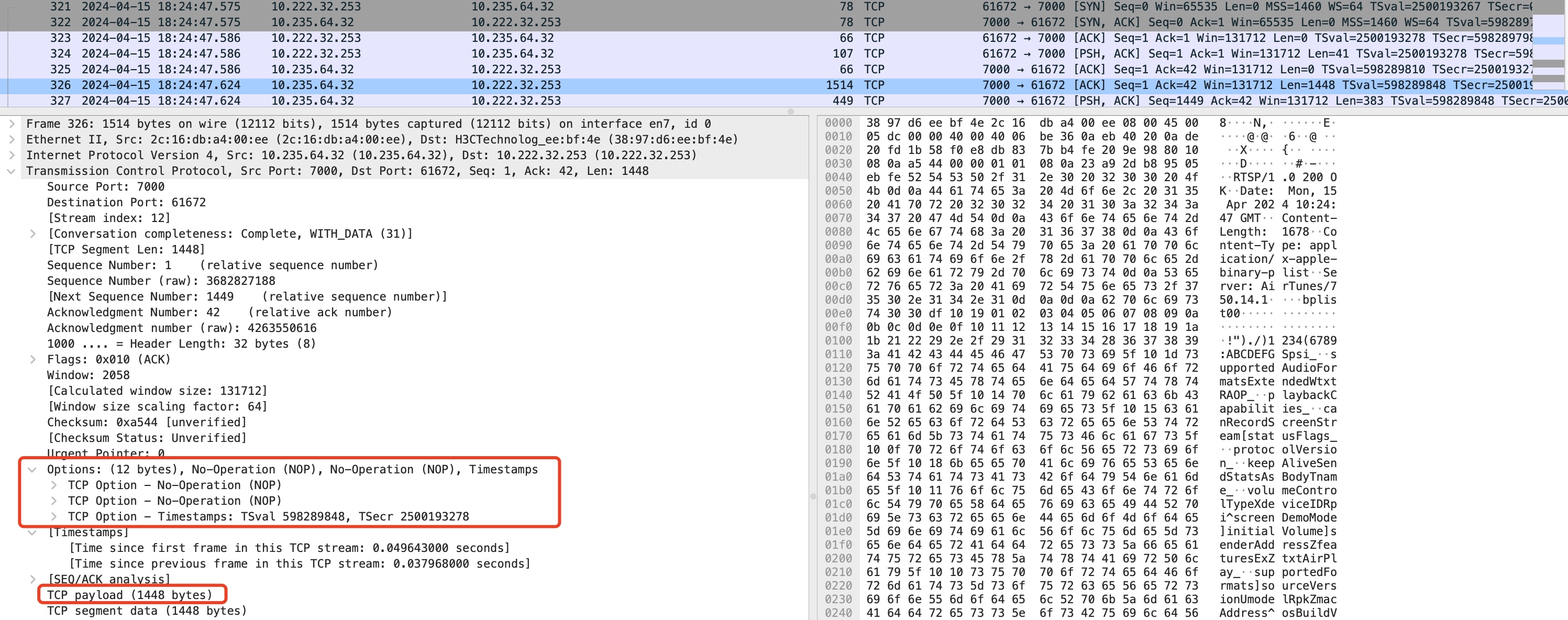
对于TCP协议来说,避免IP分片是通过在协议层通过MSS参数自己进行分好segment再提交给IP层,这样只要segment大小不超过PMTU就不会导致在IP层分片,通信双方会在三次握手阶段时双方互通告对方自己的MSS,最终双方会选择两端MSS的最小值作为传输的MSS。 如下:在TCP的SYN报文通过TCP option携带了发出端的MSS(1460),如果不带的话默认通告MSS的值是536(内核依照RFC1122, RFC2581中的规定,见宏TCP_MSS_DEFAULT)。
#define TCP_MSS_DEFAULT 536U
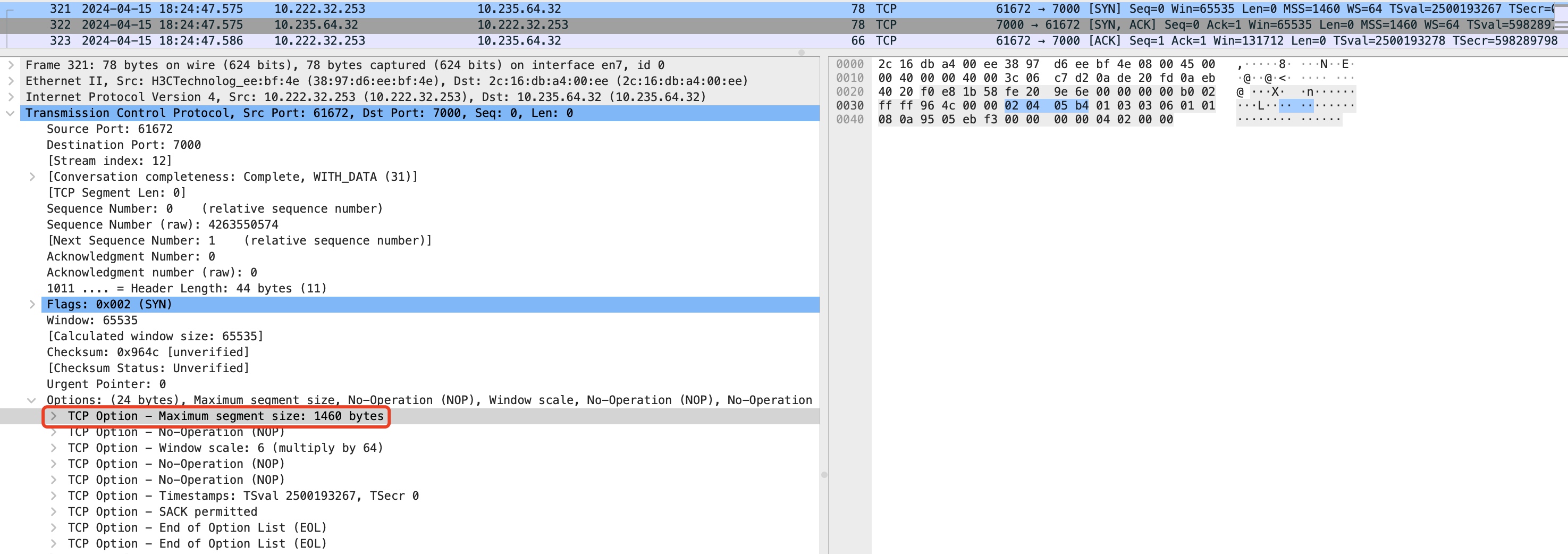
默认情况下,MSS值的计算是通过本机网络接口的默认MTU计算出来的:MSS = 网卡MTU - 20(IP头) - 20(TCP头),注意:这里通告MSS的值并不会包括IP头的option和TCP头的option,实际发送的TCP Payload还需要考虑这两个扩展项。
比如这里通告的MSS是1460,最终TCP Payload是1448,因为还有12 bytes的TCP option。
通告的MSS还可以显示进行指定,有3种方法:
- ip tables:
iptables -I OUTPUT -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1280
- ip route:
ip route change 10.35.46.0/24 dev eth0 proto kernel scope link src 10.35.46.29 metric 100 advmss 1280
- 程序层通过setsockopt的socket选项TCP_MAXSEG指定
int tcp_maxseg = mss;
socklen_t tcp_maxseg_len = sizeof(tcp_maxseg);
setsockopt(server_fd, IPPROTO_TCP, TCP_MAXSEG, &tcp_maxseg, tcp_maxseg_len)
如下示例,我在10.182.25.30机器通过iptables针对eth0网卡发出的SYN包且目的IP为10.2.22.80的握手包强制指定mss为1400,在10.2.22.80机器抓包,可以看到从10.182.25.30发给10.2.22.80的SYN包中MSS已经被iptables设置为1400了:
sudo iptables -I OUTPUT -o eth0 -d 10.2.22.80 -p tcp -m tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1400
//在10.2.22.80抓包
sudo tcpdump -i eth0 -n 'port 9999 and tcp[tcpflags]&tcp-syn!=0' -s 1024 -A
//握手包情况
15:48:38.650599 IP 10.2.22.80.32525 > 10.182.25.30.distinct: Flags [S], seq 2058602606, win 42340, options [mss 1460,sackOK,TS val 1320415385 ecr 0,nop,wscale 9], length 0
15:48:38.652391 IP 10.182.25.30.distinct > 10.2.22.80.32525: Flags [S.], seq 1130397702, ack 2058602607, win 43440, options [mss 1400,sackOK,TS val 2333229243 ecr 1320415385,nop,wscale 9], length 0
//用完后清除这条规则
sudo iptables -D OUTPUT 1
MSS Clamping(MSS钳制)
虽然TCP可以在握手阶段通过MSS通告互相来确定一个双端最小的MSS,但实际情况中,如果链路中间的设备由于MTU较小还是会出现TCP的segment在中间设备被ip fragment或者被丢弃(如果设置了DF标志位)。一个好消息是,工作在路由器上的MSS Claming能解决这个问题。MSS Claming对经过路由器的包进行嗅探,如果发现是TCP的握手SYN包,就会解析包中携带的MSS值,然后和本机的MTU经过换算得到的MSS值进行比较,如果发现SYN包中携带的MSS值比本机换算出来的MSS值大,就会使用本机换算的MSS值对SYN包中的MSS进行修改替换,这样后续双端发出的包就一定能通过当前路由器。 如cisco路由器的配置命令为:
ip tcp adjust-mss [size]
linux上基于iptables/ip6tables也支持MSS Clamping,一种是指定固定的MSS,另一种是根据MTU自适应MSS,自适应MSS方法如下:
sudo iptables -t mangle -A FORWARD -d 10.2.22.80 -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --clamp-mss-to-pmtu
PLPMTUD (Packetization-Layer Path MTU Discovery) - TCP MTU Probe
这样看,如果链路中间的所有路由器都支持MSS Claming,那么最终双端协商出来的MSS一定是整个链路中所有节点都能安全通过的值。但实际上并不是所有的路由器都支持MSS Clamping并打开的,即使链路上的路由器都支持MSS Clamping且都是打开状态,但是TCP连接建立后,路由路径也可能发生变化,可能变化后的路径和之前握手流程的路径是不一样的,不一样的路径就可能存在不一样的PMTU,所以针对TCP协议来说还是可能会存在中间链路由于路径MTU较小导致在中间被ip fragment或者被直接丢弃的问题。 因此,内核层针对TCP协议还支持在传输层维度来进行MTU探测,这个TCP功能是一个系统级别的参数,可以通过内核参数net.ipv4.tcp_mtu_probing来打开这个功能。
net.ipv4.tcp_mtu_probing = 1
0: 关闭(默认值)
1: 默认关闭,在检测到 IMCP 黑洞问题时开启
2: 始终开启,使用 tcp_base_mss 作为初始值
net.ipv4.tcp_probe_interval = 600
控制开始 PLPMTUD 重新检测的时机,默认是每 10 分钟重新检测,由 RFC4821 规定。
net.ipv4.tcp_probe_threshold = 8
控制 PLPMTUD 何时停止探测,如果最终搜索范围的间隔小于某个数字时停止,默认值是 8 字节。
探测什么时候发生
当TCP重传超过设置的sysctl_tcp_retries1值(net.ipv4.tcp_retries1默认是3)时,就会调用tcp_mtu_probing,触发MSS的调整。来看一下代码(5.14内核):
- 首先是探测参数的初始化工作,如果tcp_mtu_probing大于1(也就是始终开启模式下),icsk->icsk_mtup.enabled会被设置为1,其他模式均不会设置。MTU探测的上限值是对端mss clamp的值加上TCP头部和IP头部,探测下限值是系统参数设置的tcp_base_mss计算得到的MTU值。
/* MTU probing init per socket */
void tcp_mtup_init(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
struct net *net = sock_net(sk);
icsk->icsk_mtup.enabled = net->ipv4.sysctl_tcp_mtu_probing > 1;
icsk->icsk_mtup.search_high = tp->rx_opt.mss_clamp + sizeof(struct tcphdr) +
icsk->icsk_af_ops->net_header_len;
icsk->icsk_mtup.search_low = tcp_mss_to_mtu(sk, net->ipv4.sysctl_tcp_base_mss);
icsk->icsk_mtup.probe_size = 0;
if (icsk->icsk_mtup.enabled)
icsk->icsk_mtup.probe_timestamp = tcp_jiffies32;
}
- 当写超时发生时,如果重传超时超过sysctl_tcp_retries1值时会触发probe:
/* A write timeout has occurred. Process the after effects. */
static int tcp_write_timeout(struct sock *sk)
{
...
if (retransmits_timed_out(sk, net->ipv4.sysctl_tcp_retries1, 0)) {
/* Black hole detection */
tcp_mtu_probing(icsk, sk);
__dst_negative_advice(sk);
}
...
}
- 对于tcp_mtu_probing等于1的模式,这里仅仅会对icsk->icsk_mtup.enabled,后续在tcp_mtu_probe的逻辑里进行MTU探测;对于tcp_mtu_probing大于1(也就是始终开启模式下)模式,会直接将触发MSS下探,取探测下限计算的MSS的1/2,和系统配置的sysctl_tcp_base_mss进行比对,两者取较小值,然后在tcp_sync_mss函数中使用tcp_bound_to_half_wnd控制发送MSS与对端接收窗口的比例关系(如果当前对端最大的接收窗口大于TCP_MSS_DEFAULT(536),将发送MSS限制在最大接收窗口的一半内;否则,对于小于536的小窗口,发送MSS的值不应超出整个窗口的值),最后设置mss_cache的值取当前值和以search_low计算得到的mss值两者之间的较小值。
static void tcp_mtu_probing(struct inet_connection_sock *icsk, struct sock *sk)
{
const struct net *net = sock_net(sk);
int mss;
/* Black hole detection */
if (!net->ipv4.sysctl_tcp_mtu_probing)
return;
if (!icsk->icsk_mtup.enabled) { //模式1
icsk->icsk_mtup.enabled = 1;
icsk->icsk_mtup.probe_timestamp = tcp_jiffies32;
} else { //模式2
mss = tcp_mtu_to_mss(sk, icsk->icsk_mtup.search_low) >> 1;
mss = min(net->ipv4.sysctl_tcp_base_mss, mss);
mss = max(mss, net->ipv4.sysctl_tcp_mtu_probe_floor);
mss = max(mss, net->ipv4.sysctl_tcp_min_snd_mss);
icsk->icsk_mtup.search_low = tcp_mss_to_mtu(sk, mss);
}
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
}
/* This function synchronize snd mss to current pmtu/exthdr set.
tp->rx_opt.user_mss is mss set by user by TCP_MAXSEG. It does NOT counts
for TCP options, but includes only bare TCP header.
tp->rx_opt.mss_clamp is mss negotiated at connection setup.
It is minimum of user_mss and mss received with SYN.
It also does not include TCP options.
inet_csk(sk)->icsk_pmtu_cookie is last pmtu, seen by this function.
tp->mss_cache is current effective sending mss, including
all tcp options except for SACKs. It is evaluated,
taking into account current pmtu, but never exceeds
tp->rx_opt.mss_clamp.
NOTE1. rfc1122 clearly states that advertised MSS
DOES NOT include either tcp or ip options.
NOTE2. inet_csk(sk)->icsk_pmtu_cookie and tp->mss_cache
are READ ONLY outside this function. --ANK (980731)
*/
unsigned int tcp_sync_mss(struct sock *sk, u32 pmtu)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
int mss_now;
if (icsk->icsk_mtup.search_high > pmtu)
icsk->icsk_mtup.search_high = pmtu;
mss_now = tcp_mtu_to_mss(sk, pmtu);
mss_now = tcp_bound_to_half_wnd(tp, mss_now);
/* And store cached results */
icsk->icsk_pmtu_cookie = pmtu;
if (icsk->icsk_mtup.enabled)
mss_now = min(mss_now, tcp_mtu_to_mss(sk, icsk->icsk_mtup.search_low));
tp->mss_cache = mss_now;
return mss_now;
}
EXPORT_SYMBOL(tcp_sync_mss);
/* Bound MSS / TSO packet size with the half of the window */
static inline int tcp_bound_to_half_wnd(struct tcp_sock *tp, int pktsize)
{
int cutoff;
/* When peer uses tiny windows, there is no use in packetizing
* to sub-MSS pieces for the sake of SWS or making sure there
* are enough packets in the pipe for fast recovery.
*
* On the other hand, for extremely large MSS devices, handling
* smaller than MSS windows in this way does make sense.
*/
if (tp->max_window > TCP_MSS_DEFAULT)
cutoff = (tp->max_window >> 1);
else
cutoff = tp->max_window;
if (cutoff && pktsize > cutoff)
return max_t(int, cutoff, 68U - tp->tcp_header_len);
else
return pktsize;
}
- 接下来看下tcp发送数据的函数tcp_write_xmit,对于非紧急的数据发送(非push类型)则会进入tcp_mtu_probe流程,注意这里使用的是业务自身要发送的数据加上DF标志位来进行探测。
/* This routine writes packets to the network. It advances the
* send_head. This happens as incoming acks open up the remote
* window for us.
*
* LARGESEND note: !tcp_urg_mode is overkill, only frames between
* snd_up-64k-mss .. snd_up cannot be large. However, taking into
* account rare use of URG, this is not a big flaw.
*
* Send at most one packet when push_one > 0. Temporarily ignore
* cwnd limit to force at most one packet out when push_one == 2.
* Returns true, if no segments are in flight and we have queued segments,
* but cannot send anything now because of SWS or another problem.
*/
static bool tcp_write_xmit(struct sock *sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb;
unsigned int tso_segs, sent_pkts;
int cwnd_quota;
int result;
bool is_cwnd_limited = false, is_rwnd_limited = false;
u32 max_segs;
sent_pkts = 0;
tcp_mstamp_refresh(tp);
if (!push_one) {
/* Do MTU probing. */
result = tcp_mtu_probe(sk);
if (!result) {
return false;
} else if (result > 0) {
sent_pkts = 1;
}
}
...
}
- 最后是探测的流程函数。如果没有正在运行的探测、拥塞状态在初始态、发送拥塞窗口大于11,并且没有SACK、待发送队列有足够的数据用于探测,以上条件只要有一个不满足,就不能进行MTU探测。对于满足MTU探测的,探测的报文大小probe_size等于search_low + (search_high - search_low) / 2 转换得到的MSS值,作为传输的探测值,有点类似一个binary search的算法。如果最终计算出来的probe_size大于search_high或者searh_high和search_low的gap已经小于系统参数ipv4.sysctl_tcp_probe_threshold的阈值,那么当次探测取消,进入tcp_mtu_check_reprobe逻辑,这里会判断是否reprobe逻辑里上次探测间隔了至少ipv4.sysctl_tcp_probe_interval(默认600s),如果满足条件,reprobe会使用当前mss作为search_low,对端clamp的mss作为search_high,重新等待下一次发送数据时进入tcp_mtu_probe重新走探测流程。
- 对于tcp_mtu_probing为1的模式(仅在识别到ICMP black hole的时候触发)时,search_low初始化是sysctl_tcp_base_mss(默认1024),因此这种模式会从1024开始往上探测,直到接近达到对端握手时声明的MSS clamp时为止。
- 对于tcp_mtu_probing为2的模式(始终开启)时,只要重传超时次数达到sysctl_tcp_retries1就会在tcp_mtu_probing函数中对search_low被很激进的调整为当前MSS和sysctl_tcp_base_mss两者较小值的1/2,所以探测的起点会比较小(小于512)。这也是2这种“始终开启”模式的弊端,这样如果是网络本身不太好,重传次数比较多,就很容易导致最终生效的MSS在一个比较低的水平线徘徊,导致发送效率低。
确定好探测报文的大小后,内核将将开始组建数据长度为probe_size值的探测报文,新分配一个nskb,将发送队列sk_write_queue前端的数据包拷贝probe_size的数据到新的nskb中,释放拷贝过的数据包,后面的代码也是一些合法性检查,比如发送缓存中是否有足够的数据(TCP探测报文不可能“伪造”数据),发送窗口是否有足够的大小等,最后根据probe_size进行数据组建封装和发送。
/* Create a new MTU probe if we are ready.
* MTU probe is regularly attempting to increase the path MTU by
* deliberately sending larger packets. This discovers routing
* changes resulting in larger path MTUs.
*
* Returns 0 if we should wait to probe (no cwnd available),
* 1 if a probe was sent,
* -1 otherwise
*/
static int tcp_mtu_probe(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *skb, *nskb, *next;
struct net *net = sock_net(sk);
int probe_size;
int size_needed;
int copy, len;
int mss_now;
int interval;
/* Not currently probing/verifying,
* not in recovery,
* have enough cwnd, and
* not SACKing (the variable headers throw things off)
*/
if (likely(!icsk->icsk_mtup.enabled ||
icsk->icsk_mtup.probe_size ||
inet_csk(sk)->icsk_ca_state != TCP_CA_Open ||
tp->snd_cwnd < 11 ||
tp->rx_opt.num_sacks || tp->rx_opt.dsack))
return -1;
/* Use binary search for probe_size between tcp_mss_base,
* and current mss_clamp. if (search_high - search_low)
* smaller than a threshold, backoff from probing.
*/
mss_now = tcp_current_mss(sk);
probe_size = tcp_mtu_to_mss(sk, (icsk->icsk_mtup.search_high +
icsk->icsk_mtup.search_low) >> 1);
size_needed = probe_size + (tp->reordering + 1) * tp->mss_cache;
interval = icsk->icsk_mtup.search_high - icsk->icsk_mtup.search_low;
/* When misfortune happens, we are reprobing actively,
* and then reprobe timer has expired. We stick with current
* probing process by not resetting search range to its orignal.
*/
if (probe_size > tcp_mtu_to_mss(sk, icsk->icsk_mtup.search_high) ||
interval < net->ipv4.sysctl_tcp_probe_threshold) {
/* Check whether enough time has elaplased for
* another round of probing.
*/
tcp_mtu_check_reprobe(sk);
return -1;
}
/* Have enough data in the send queue to probe? */
if (tp->write_seq - tp->snd_nxt < size_needed)
return -1;
if (tp->snd_wnd < size_needed)
return -1;
if (after(tp->snd_nxt + size_needed, tcp_wnd_end(tp)))
return 0;
/* Do we need to wait to drain cwnd? With none in flight, don't stall */
if (tcp_packets_in_flight(tp) + 2 > tp->snd_cwnd) {
if (!tcp_packets_in_flight(tp))
return -1;
else
return 0;
}
if (!tcp_can_coalesce_send_queue_head(sk, probe_size))
return -1;
/* We're allowed to probe. Build it now. */
nskb = sk_stream_alloc_skb(sk, probe_size, GFP_ATOMIC, false);
if (!nskb)
return -1;
sk_wmem_queued_add(sk, nskb->truesize);
sk_mem_charge(sk, nskb->truesize);
skb = tcp_send_head(sk);
skb_copy_decrypted(nskb, skb);
mptcp_skb_ext_copy(nskb, skb);
TCP_SKB_CB(nskb)->seq = TCP_SKB_CB(skb)->seq;
TCP_SKB_CB(nskb)->end_seq = TCP_SKB_CB(skb)->seq + probe_size;
TCP_SKB_CB(nskb)->tcp_flags = TCPHDR_ACK;
TCP_SKB_CB(nskb)->sacked = 0;
nskb->csum = 0;
nskb->ip_summed = CHECKSUM_PARTIAL;
tcp_insert_write_queue_before(nskb, skb, sk);
tcp_highest_sack_replace(sk, skb, nskb);
len = 0;
tcp_for_write_queue_from_safe(skb, next, sk) {
copy = min_t(int, skb->len, probe_size - len);
skb_copy_bits(skb, 0, skb_put(nskb, copy), copy);
if (skb->len <= copy) {
/* We've eaten all the data from this skb.
* Throw it away. */
TCP_SKB_CB(nskb)->tcp_flags |= TCP_SKB_CB(skb)->tcp_flags;
/* If this is the last SKB we copy and eor is set
* we need to propagate it to the new skb.
*/
TCP_SKB_CB(nskb)->eor = TCP_SKB_CB(skb)->eor;
tcp_skb_collapse_tstamp(nskb, skb);
tcp_unlink_write_queue(skb, sk);
sk_wmem_free_skb(sk, skb);
} else {
TCP_SKB_CB(nskb)->tcp_flags |= TCP_SKB_CB(skb)->tcp_flags &
~(TCPHDR_FIN|TCPHDR_PSH);
if (!skb_shinfo(skb)->nr_frags) {
skb_pull(skb, copy);
} else {
__pskb_trim_head(skb, copy);
tcp_set_skb_tso_segs(skb, mss_now);
}
TCP_SKB_CB(skb)->seq += copy;
}
len += copy;
if (len >= probe_size)
break;
}
tcp_init_tso_segs(nskb, nskb->len);
/* We're ready to send. If this fails, the probe will
* be resegmented into mss-sized pieces by tcp_write_xmit().
*/
if (!tcp_transmit_skb(sk, nskb, 1, GFP_ATOMIC)) {
/* Decrement cwnd here because we are sending
* effectively two packets. */
tp->snd_cwnd--;
tcp_event_new_data_sent(sk, nskb);
icsk->icsk_mtup.probe_size = tcp_mss_to_mtu(sk, nskb->len);
tp->mtu_probe.probe_seq_start = TCP_SKB_CB(nskb)->seq;
tp->mtu_probe.probe_seq_end = TCP_SKB_CB(nskb)->end_seq;
return 1;
}
return -1;
}
static inline void tcp_mtu_check_reprobe(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
u32 interval;
s32 delta;
interval = net->ipv4.sysctl_tcp_probe_interval;
delta = tcp_jiffies32 - icsk->icsk_mtup.probe_timestamp;
if (unlikely(delta >= interval * HZ)) {
int mss = tcp_current_mss(sk);
/* Update current search range */
icsk->icsk_mtup.probe_size = 0;
icsk->icsk_mtup.search_high = tp->rx_opt.mss_clamp +
sizeof(struct tcphdr) +
icsk->icsk_af_ops->net_header_len;
icsk->icsk_mtup.search_low = tcp_mss_to_mtu(sk, mss);
/* Update probe time stamp */
icsk->icsk_mtup.probe_timestamp = tcp_jiffies32;
}
}
如果发出的探测包被判定为探测失败,在tcp_fastretrans_alert函数中,会触发tcp_mtup_probe_failed处理探测失败的场景,在这里会将当前探测值减1作为探测上限search_high,等待下次tcp_mtu_probe再次进行探测。
/* Process an event, which can update packets-in-flight not trivially.
* Main goal of this function is to calculate new estimate for left_out,
* taking into account both packets sitting in receiver's buffer and
* packets lost by network.
*
* Besides that it updates the congestion state when packet loss or ECN
* is detected. But it does not reduce the cwnd, it is done by the
* congestion control later.
*
* It does _not_ decide what to send, it is made in function
* tcp_xmit_retransmit_queue().
*/
static void tcp_fastretrans_alert(struct sock *sk, const u32 prior_snd_una,
int num_dupack, int *ack_flag, int *rexmit)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
int fast_rexmit = 0, flag = *ack_flag;
bool ece_ack = flag & FLAG_ECE;
bool do_lost = num_dupack || ((flag & FLAG_DATA_SACKED) &&
tcp_force_fast_retransmit(sk));
if (!tp->packets_out && tp->sacked_out)
tp->sacked_out = 0;
/* Now state machine starts.
* A. ECE, hence prohibit cwnd undoing, the reduction is required. */
if (ece_ack)
tp->prior_ssthresh = 0;
/* B. In all the states check for reneging SACKs. */
if (tcp_check_sack_reneging(sk, flag))
return;
/* C. Check consistency of the current state. */
tcp_verify_left_out(tp);
/* D. Check state exit conditions. State can be terminated
* when high_seq is ACKed. */
if (icsk->icsk_ca_state == TCP_CA_Open) {
WARN_ON(tp->retrans_out != 0 && !tp->syn_data);
tp->retrans_stamp = 0;
} else if (!before(tp->snd_una, tp->high_seq)) {
switch (icsk->icsk_ca_state) {
case TCP_CA_CWR:
/* CWR is to be held something *above* high_seq
* is ACKed for CWR bit to reach receiver. */
if (tp->snd_una != tp->high_seq) {
tcp_end_cwnd_reduction(sk);
tcp_set_ca_state(sk, TCP_CA_Open);
}
break;
case TCP_CA_Recovery:
if (tcp_is_reno(tp))
tcp_reset_reno_sack(tp);
if (tcp_try_undo_recovery(sk))
return;
tcp_end_cwnd_reduction(sk);
break;
}
}
/* E. Process state. */
switch (icsk->icsk_ca_state) {
case TCP_CA_Recovery:
if (!(flag & FLAG_SND_UNA_ADVANCED)) {
if (tcp_is_reno(tp))
tcp_add_reno_sack(sk, num_dupack, ece_ack);
} else if (tcp_try_undo_partial(sk, prior_snd_una, &do_lost))
return;
if (tcp_try_undo_dsack(sk))
tcp_try_keep_open(sk);
tcp_identify_packet_loss(sk, ack_flag);
if (icsk->icsk_ca_state != TCP_CA_Recovery) {
if (!tcp_time_to_recover(sk, flag))
return;
/* Undo reverts the recovery state. If loss is evident,
* starts a new recovery (e.g. reordering then loss);
*/
tcp_enter_recovery(sk, ece_ack);
}
break;
case TCP_CA_Loss:
tcp_process_loss(sk, flag, num_dupack, rexmit);
tcp_identify_packet_loss(sk, ack_flag);
if (!(icsk->icsk_ca_state == TCP_CA_Open ||
(*ack_flag & FLAG_LOST_RETRANS)))
return;
/* Change state if cwnd is undone or retransmits are lost */
fallthrough;
default:
if (tcp_is_reno(tp)) {
if (flag & FLAG_SND_UNA_ADVANCED)
tcp_reset_reno_sack(tp);
tcp_add_reno_sack(sk, num_dupack, ece_ack);
}
if (icsk->icsk_ca_state <= TCP_CA_Disorder)
tcp_try_undo_dsack(sk);
tcp_identify_packet_loss(sk, ack_flag);
if (!tcp_time_to_recover(sk, flag)) {
tcp_try_to_open(sk, flag);
return;
}
/* MTU probe failure: don't reduce cwnd */
if (icsk->icsk_ca_state < TCP_CA_CWR &&
icsk->icsk_mtup.probe_size &&
tp->snd_una == tp->mtu_probe.probe_seq_start) {
tcp_mtup_probe_failed(sk);
/* Restores the reduction we did in tcp_mtup_probe() */
tp->snd_cwnd++;
tcp_simple_retransmit(sk);
return;
}
/* Otherwise enter Recovery state */
tcp_enter_recovery(sk, ece_ack);
fast_rexmit = 1;
}
if (!tcp_is_rack(sk) && do_lost)
tcp_update_scoreboard(sk, fast_rexmit);
*rexmit = REXMIT_LOST;
}
static void tcp_mtup_probe_failed(struct sock *sk)
{
struct inet_connection_sock *icsk = inet_csk(sk);
icsk->icsk_mtup.search_high = icsk->icsk_mtup.probe_size - 1;
icsk->icsk_mtup.probe_size = 0;
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPMTUPFAIL);
}
TCP在处理ACK报文时,会在函数tcp_clean_rtx_queue检查和清空重传队列,在这里的逻辑里判定是否当次探测成功,在tcp_mtup_probe_success会处理探测成功的后续逻辑,随即将探测值probe_size赋予MTU探测的下限值,复位probe_size。由函数tcp_sync_mss同步TCP的MSS值。
static void tcp_mtup_probe_success(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
/* FIXME: breaks with very large cwnd */
tp->prior_ssthresh = tcp_current_ssthresh(sk);
tp->snd_cwnd = tp->snd_cwnd *
tcp_mss_to_mtu(sk, tp->mss_cache) /
icsk->icsk_mtup.probe_size;
tp->snd_cwnd_cnt = 0;
tp->snd_cwnd_stamp = tcp_jiffies32;
tp->snd_ssthresh = tcp_current_ssthresh(sk);
icsk->icsk_mtup.search_low = icsk->icsk_mtup.probe_size;
icsk->icsk_mtup.probe_size = 0;
tcp_sync_mss(sk, icsk->icsk_pmtu_cookie);
NET_INC_STATS(sock_net(sk), LINUX_MIB_TCPMTUPSUCCESS);
}
至此,TCP基于协议层的PLPMTUD的逻辑基本就理清了,基本上就是在TCP发送数据时,从TCP待发送队列sk_write_queue中拿出一部分数据按照计算得到的probe_size大小进行封装发送,探测包大小probe_size采用类似二分查找的方式来逐步探测到一个比较接近上限的MTU值。由于前面提到的tcp_mtu_probing为2的模式(始终开启)下,每次重传次数达到默认的3次时会将探测的下限很激进的直接下探到512甚至更低,这样对于传输效率不是一个好的选择。所以,对于存在ICMP black hole的场景,建议打开tcp_mtu_probing且设置为1,这样探测下限(默认1024)没那么低,不容易受弱网的影响,相对更合理一些。
抓包详细分析一下tcp_mtu_probing为1的MTU探测流程:
-
准备3台设备,分别为:服务端:10.182.25.30,路由机器:10.2.25.31,客户端:10.2.22.80,客户端通过tcp和服务端进行通信,如果服务端收到某一个特定数据,会给客户端发送一个数据量较大的响应报文。
-
服务端10.182.25.30和客户端10.2.22.80的MTU均为1460,宣告的clamp MSS都是1460,在路由机器10.2.25.31调整网卡MTU为1430,服务端和客户端均开启net.ipv4.ip_no_pmtu_disc,这样默认发出的IP包都会设置DF标志位,服务端设置tcp_mtu_probing为1,表示支持在出现ICMP black hole时触发tcp mtu probe。
sudo ifconfig eth0 mtu 1430 -
在路由机器10.2.25.31设置1条DNAT转发规则,将收到的所有来自于10.2.22.80且请求到10.2.25.31的TCP 9999端口的流量都转发到服务端10.182.25.30的9999端口;
sudo iptables -t nat -A PREROUTING -p tcp -s 10.2.22.80 -d 10.2.25.31 --dport 9999 -j DNAT --to 10.182.25.30:9999 -
在路由机10.2.25.31设置1条SNAT转发规则,所有来自客户端10.2.22.80将要发给服务器10.182.25.30的9999端口包的源地址都从10.2.22.80改成路由机10.2.25.31本身,这样服务端10.182.25.30看到的包都是路由机发过来的;
sudo iptables -t nat -A POSTROUTING -p tcp -s 10.2.22.80 -d 10.182.25.30 --dport 9999 -j SNAT --to 10.2.25.31 -
在路由机10.2.25.31查看下NAT路由:
sudo iptables -t nat -L -
在服务端iptables配置扔掉来自10.2.25.31的code 4的icmp包,模拟ICMP black hole:
sudo iptables -A INPUT -p icmp -s 10.2.25.31 -j DROP --icmp-type fragmentation-needed
-
服务端server.py程序开启,支持回显客户端发送的指令,针对特定指令返回超长数据:
import socketserver client_list=[] class TCPHandler(socketserver.BaseRequestHandler): # 所有请求的交互都是在handle里执行的 def handle(self): while True: try: # 每一个请求都会实例化TCPHandler(socketserver.BaseRequestHandler): self.data = self.request.recv(80000).strip() client_ip=self.client_address[0] client_num=self.client_address[1] if client_num not in client_list: client_list.append(client_num) print("来访客户端IP:{} 编号:{}".format(client_ip,client_num)) if not self.data.decode().strip(): print("客户端:{} 已经断开".format(client_num)) client_list.remove(client_num) break if self.data.decode().strip() == "test": self.request.sendall("hello===忽略重复,大约7000byte".encode()) print("发送超长数据") else: print("客户端数据:",self.data.decode()) #发送回客户端的数据 self.request.sendall(self.data) print("-------当前在线客户端编号列表-----------") print(client_list) except ConnectionResetError as e: print("----断开的客户端------") print("客户端:{} 已经断开".format(client_num)) #如果有客户端掉线,则将它从在线列表中删除 client_list.remove(client_num) break if __name__ == "__main__": HOST, PORT = "0.0.0.0", 9999 server = socketserver.ThreadingTCPServer((HOST, PORT), TCPHandler) #线程 server.serve_forever() -
客户端client.py,支持给服务端发送指令和回显服务端传回的数据:
import socket import time class Client(): def send_info(self): client = socket.socket() # 定义协议类型,相当于生命socket类型,同时生成socket连接对象 client.connect(('10.2.25.31', 9999)) client.setblocking(False) while True: msg = input(">>>").strip() if len(msg) == 0: continue client.send(msg.encode("utf-8")) data = "" while True: try: time.sleep(1) temp = client.recv(8192) # 这里是字节1k if temp: data = data + temp.decode() continue except BlockingIOError as e: if data: print("recv:>", data) break else: continue except KeyboardInterrupt: print("===end conversation===") if __name__ == "__main__": client = Client() client.send_info() -
服务端10.182.25.30抓包:
16:34:44.873659 IP 10.2.25.31.44715 > 10.182.25.30.distinct: Flags [S], seq 3895174371, win 42340, options [mss 1460,sackOK,TS val 920814268 ecr 0,nop,wscale 9], length 0 16:34:44.873701 IP 10.182.25.30.distinct > 10.2.25.31.44715: Flags [S.], seq 2833204471, ack 3895174372, win 43440, options [mss 1460,sackOK,TS val 3626655078 ecr 920814268,nop,wscale 9], length 0 E..<..@.@... 16:34:44.875840 IP 10.2.25.31.44715 > 10.182.25.30.distinct: Flags [.], ack 1, win 83, options [nop,nop,TS val 920814270 ecr 3626655078], length 0 -
客户端10.2.22.80抓包:
16:25:59.210783 IP 10.2.22.80.expresspay > 10.2.25.31.distinct: Flags [S], seq 1589953842, win 42340, options [mss 1460,sackOK,TS val 920288606 ecr 0,nop,wscale 9], length 0 16:25:59.212969 IP 10.2.25.31.distinct > 10.2.22.80.expresspay: Flags [S.], seq 3279612184, ack 1589953843, win 43440, options [mss 1460,sackOK,TS val 3626129416 ecr 920288606,nop,wscale 9], length 0 16:25:59.212995 IP 10.2.22.80.expresspay > 10.2.25.31.distinct: Flags [.], ack 1, win 83, options [nop,nop,TS val 920288608 ecr 3626129416], length 0 -
路由机10.2.25.31上抓包:
16:32:41.824173 IP 10.2.22.80.20501 > 10.2.25.31.distinct: Flags [S], seq 2612701085, win 42340, options [mss 1460,sackOK,TS val 920691220 ecr 0,nop,wscale 9], length 0 16:32:41.824354 IP 10.2.25.31.20501 > 10.182.25.30.distinct: Flags [S], seq 2612701085, win 42340, options [mss 1460,sackOK,TS val 920691220 ecr 0,nop,wscale 9], length 0 16:32:41.826350 IP 10.182.25.30.distinct > 10.2.25.31.20501: Flags [S.], seq 1087659627, ack 2612701086, win 43440, options [mss 1460,sackOK,TS val 3626532029 ecr 920691220,nop,wscale 9], length 0 16:32:41.826393 IP 10.2.25.31.distinct > 10.2.22.80.20501: Flags [S.], seq 1087659627, ack 2612701086, win 43440, options [mss 1460,sackOK,TS val 3626532029 ecr 920691220,nop,wscale 9], length 0 16:32:41.826522 IP 10.2.22.80.20501 > 10.2.25.31.distinct: Flags [.], ack 1, win 83, options [nop,nop,TS val 920691222 ecr 3626532029], length 0 16:32:41.826530 IP 10.2.25.31.20501 > 10.182.25.30.distinct: Flags [.], ack 1, win 83, options [nop,nop,TS val 920691222 ecr 3626532029], length 0
从握手抓包可以看到,服务端和客户端的IP报文经过路由机后,各自宣告的MSS都是1460,并没有察觉到路由机本身MTU变小。
-
通过bpftrace监测服务端10.182.25.30是否有正常触发tcp_mtu_probe。
sudo bpftrace -e 'kretprobe:tcp_mtu_probe / pid==3415470/ {printf("===tcp_mtu_probe, pid is : %d, return is: %d, call stack:%s\n",pid, retval, kstack)}' -
通过systemtap监测服务端10.182.25.30在进入tcp_mtu_probe函数后的各项数据细节,tcp_mtu_probe.stp:
#!/usr/bin/env stap probe kernel.statement("tcp_mtu_probe@net/ipv4/tcp_output.c:2338") { if (pid() == target()) { printf("icsk->icsk_mtup.enabled is:%d, icsk->icsk_mtup.probe_size is: %d, tp->snd_cwnd is: %d, tp->rx_opt.num_sacks is: %d, tp->rx_opt.dsack is: %d, ca state:%d, search_low is :%d, search_high is: %d,tp->reordering=%d, tp->mss_cache=%d, tp->seq-gap=%d, size_needed=%d\n", $icsk->icsk_mtup->enabled, $icsk->icsk_mtup->probe_size, $tp->snd_cwnd, $tp->rx_opt->num_sacks, $tp->rx_opt->dsack, $icsk->icsk_ca_state, $icsk->icsk_mtup->search_low, $icsk->icsk_mtup->search_high, $tp->reordering, $tp->mss_cache, $tp->write_seq - $tp->snd_nxt,($icsk->icsk_mtup->search_high+$icsk->icsk_mtup->search_low)/2 + ($tp->reordering + 1) * $tp->mss_cache); print_backtrace(); } }监听起来:sudo /usr/bin/stap -x 3415470 tcp_mtu_probe.stp
详细模拟流程
- client给server多次交替发送hello指令和test指令,服务端根据指令不同回复不同长度内容(hello回显,test发回超长内容);
- 抓包发现,在服务端没有给客户端发送超长数据时,虽然每次数据发送都会通过tcp_write_xmit进入tcp_mtu_probe逻辑,但是都不会被真正触发探测,一直返回-1,因为较短的数据时能够传回给客户端的,tcp_mtu_probe函数中的探测逻辑没有被触发的原因主要是因为icsk->icsk_mtup.enabled是0。
===tcp_mtu_probe, pid is : 3415470, return is: -1, call stack: tcp_write_xmit+90 __tcp_push_pending_frames+50 tcp_sendmsg_locked+2156 tcp_sendmsg+40 sock_sendmsg+91 __sys_sendto+240 __x64_sys_sendto+32 do_syscall_64+89 entry_SYSCALL_64_after_hwframe+99icsk->icsk_mtup.enabled is:0, icsk->icsk_mtup.probe_size is: 0, tp->snd_cwnd is: 10, tp->rx_opt.num_sacks is: 0, tp->rx_opt.dsack is: 0, ca state:0, search_low is :1076, search_high is: 1500,tp->reordering=3, tp->mss_cache=1448, tp->seq-gap=5, size_needed=7080 0xffffffffaf3bbe17 : tcp_mtu_probe+0x17/0x660 [kernel] 0xffffffffaea6b6c0 : arch_rethook_trampoline+0x0/0x60 [kernel] icsk->icsk_mtup.enabled is:0, icsk->icsk_mtup.probe_size is: 0, tp->snd_cwnd is: 11, tp->rx_opt.num_sacks is: 0, tp->rx_opt.dsack is: 0, ca state:0, search_low is :1076, search_high is: 1500,tp->reordering=3, tp->mss_cache=1448, tp->seq-gap=5, size_needed=7080 0xffffffffaf3bbe17 : tcp_mtu_probe+0x17/0x660 [kernel] 0xffffffffaea6b6c0 : arch_rethook_trampoline+0x0/0x60 [kernel] icsk->icsk_mtup.enabled is:0, icsk->icsk_mtup.probe_size is: 0, tp->snd_cwnd is: 12, tp->rx_opt.num_sacks is: 0, tp->rx_opt.dsack is: 0, ca state:0, search_low is :1076, search_high is: 1500,tp->reordering=3, tp->mss_cache=1448, tp->seq-gap=5, size_needed=7080 - 当服务端在第一次接收到test指令回显超长内容给客户端的时候,会触发重传策略:因为根据双方协商的MSS,服务端会针对超长数据按照Clamp MSS 1460来进行分包,但是在经过路由机的时候由于路由机MTU小,超过MTU 1430的包会被丢弃掉,导致服务端收不到ACK触发重传;
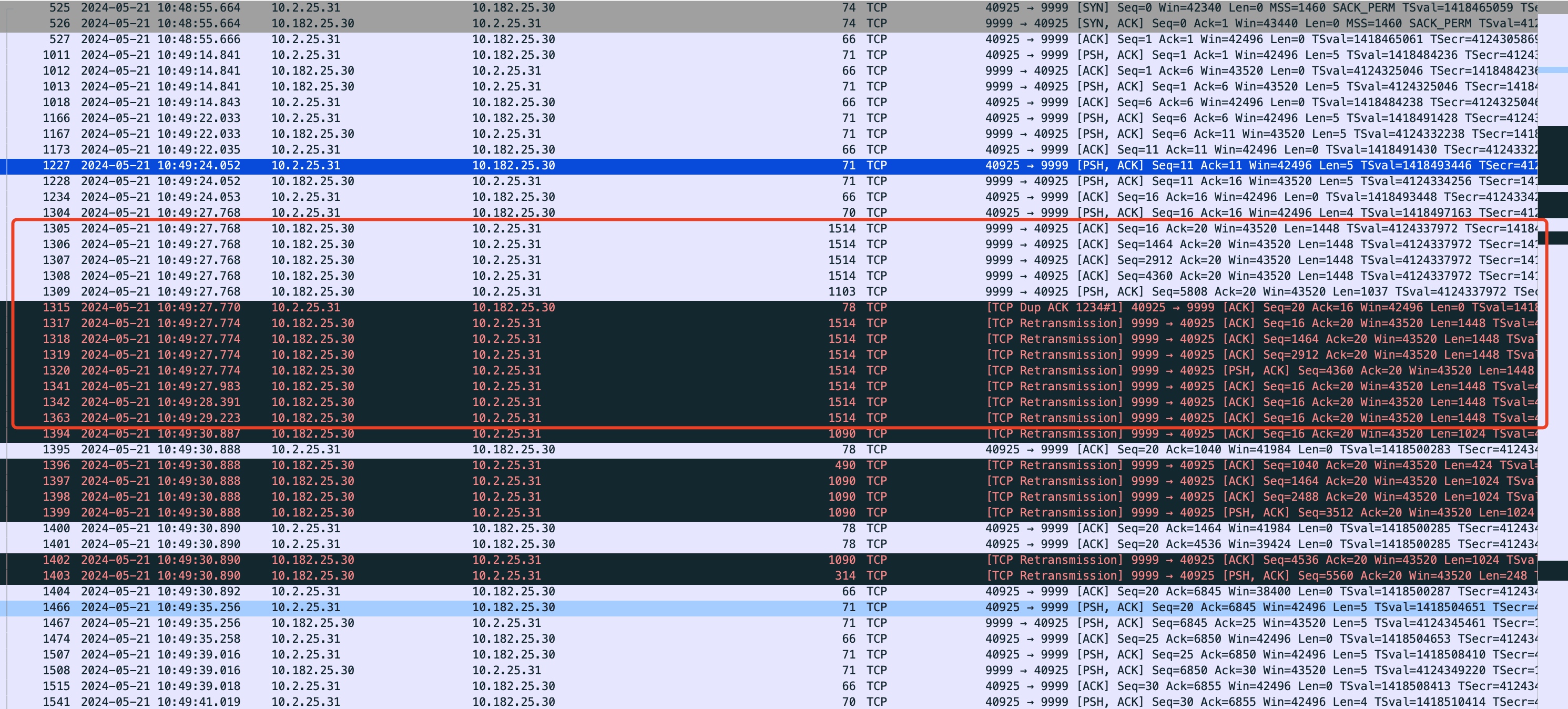
- 由于服务端tcp_mtu_probing设置为1,此时,超时重传达到net.ipv4.tcp_retries1会触发tcp_mtu_probing,在tcp_mtu_probing函数里,会将icsk_mtup.enabled设置为1(打开),同时通过tcp_sync_mss函数,将连接初始化时tcp_mtup_init设置的mtu的search_low(1024)设置给当前的mss,因此,可以看到之前发送失败的包再次重新发出,限制在使用mss为1024对应的mtu大小范围内,如下抓包,这些显示为1090的重传包都是对应的mss为1024。
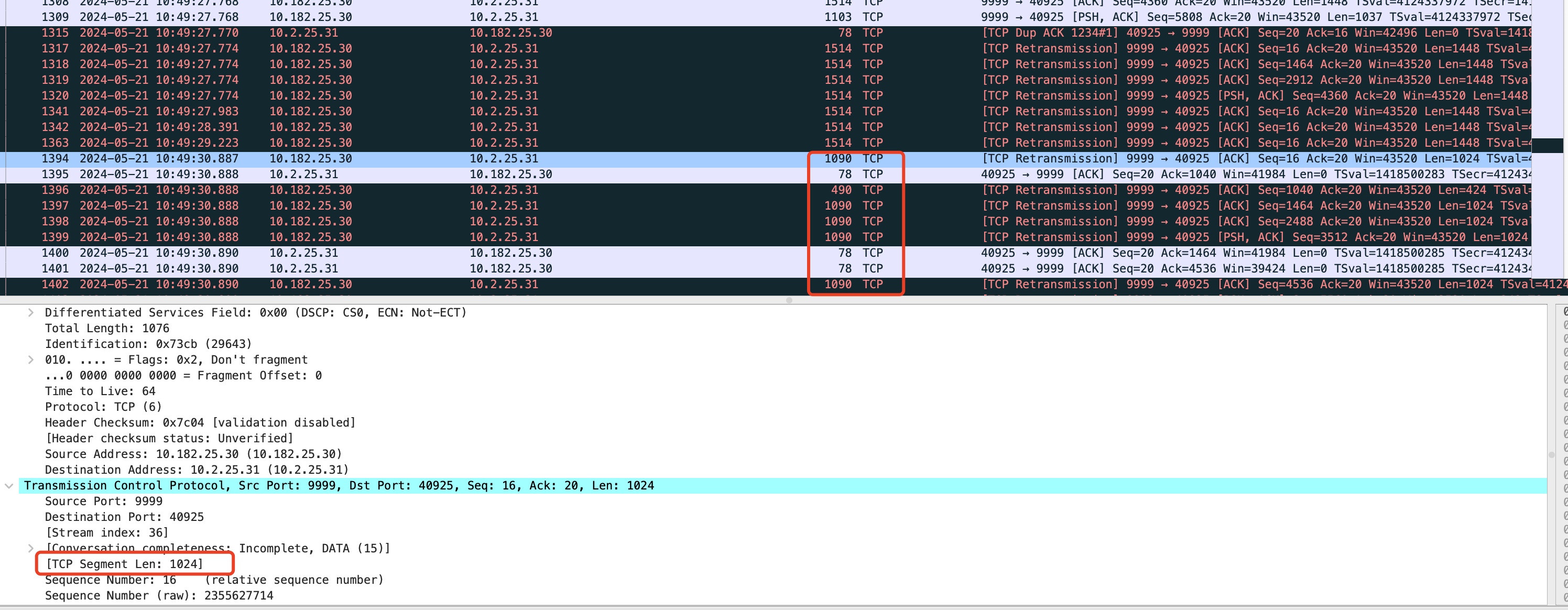
- 因为mss在触发重传net.ipv4.tcp_retries1后mss被调整为1024大小,同时icsk_mtup.enabled被打开(为1),为了能尽量提升发送效率避免一直运行在mss 1024的基线水平,后续有数据再次通过tcp_write_xmit发送的时候,在tcp_mtu_probe函数中,各项探测逻辑如果满足,就会进入使用应用层数据进行mtu向上探测。
===tcp_mtu_probe, pid is : 3415470, return is: 1, call stack: tcp_write_xmit+90 __tcp_push_pending_frames+50 tcp_sendmsg_locked+2156 tcp_sendmsg+40 sock_sendmsg+91 __sys_sendto+240 __x64_sys_sendto+32 do_syscall_64+89 entry_SYSCALL_64_after_hwframe+99icsk->icsk_mtup.enabled is:1, icsk->icsk_mtup.probe_size is: 0, tp->snd_cwnd is: 18, tp->rx_opt.num_sacks is: 0, tp->rx_opt.dsack is: 0, ca state:0, search_low is :1076, search_high is: 1500,tp->reordering=3, tp->mss_cache=1024, tp->seq-gap=6829, size_needed=5384- 可以看到,在第二次再发送test指令触发了tcp_mtu_probe的mtu向上探测流程(探测条件都满足:没有正在运行的探测、拥塞状态在初始态、发送拥塞窗口大于11,并且没有SACK、待发送队列有足够的数据用于探测),探测前的mss是1024,当时mtu的search_low是1076,search_high是1500,由代码公式可以得出,本次向上探测的mtu为 (1076 + 1500)/ 2 = 1288,并且抓包可以看到此次探测包。
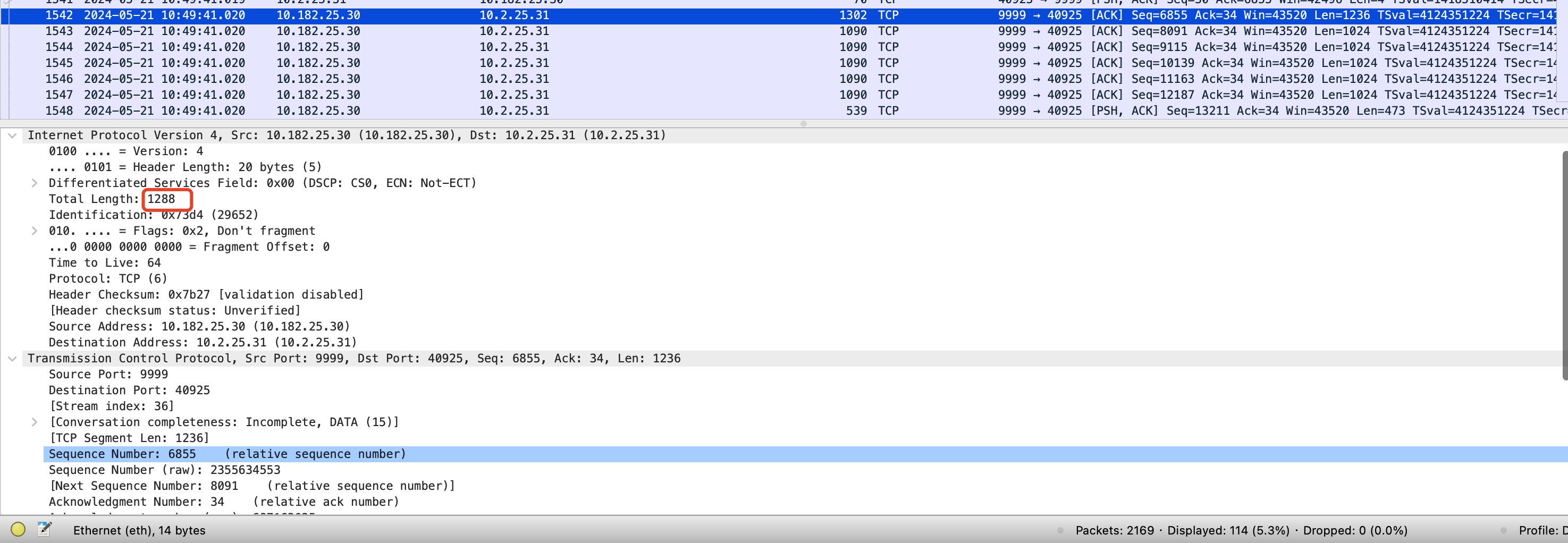 需要注意的是:在该探测包还没有被ACK确认时,在这个gap时间差中可以看到其他的包还是沿用旧的MSS 1024来组装数据(如上图1302包后面的那些1090大小的包)。
需要注意的是:在该探测包还没有被ACK确认时,在这个gap时间差中可以看到其他的包还是沿用旧的MSS 1024来组装数据(如上图1302包后面的那些1090大小的包)。 - 在mtu 1288探测成功后,当前的MSS被设置为1236(1288 - 20tcp头 - 12tcp时间戳选项 - 20ip头),探测的search_low被设置为1288,服务端在下一次有符合要求的数据要发出时,会继续向上探测MTU,由公式可知:当前search_low=1288,search_high=1500,向上探测的MTU为: (1288 + 1500) / 2 = 1394。该探测包可以抓包看到如下:
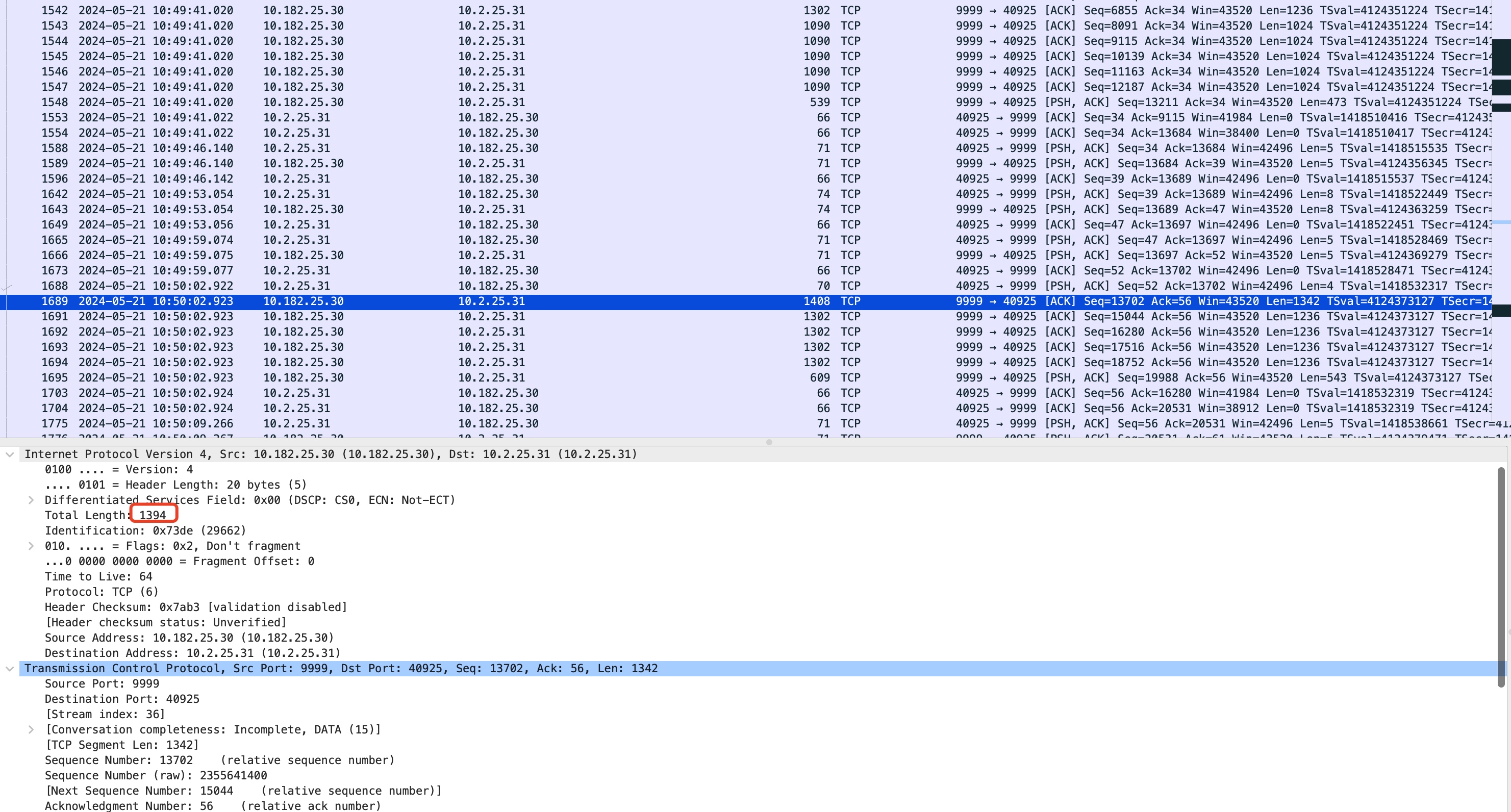
- 同样的,本次探测包被成功ACK确认后,会将MSS设置为1342,下次探测的search_low被设置为1394,下一次向上探测的MTU为: (1394 + 1500) / 2 = 1447。该探测包可以抓包看到如下:
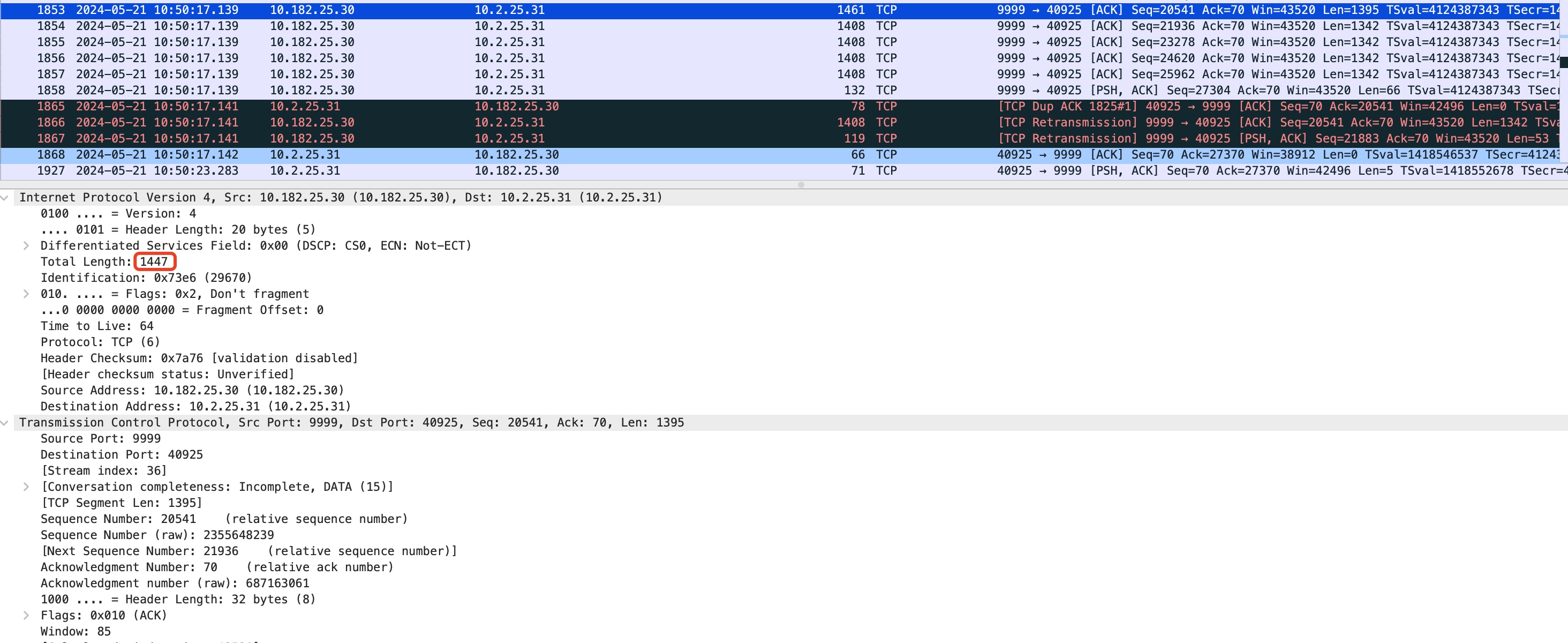 但这一次发出的1447的探测包由于中间路由机的MTU只有1430所以被丢弃了,因此会触发tcp_mtup_probe_failed的探测失败逻辑,探测的search_high被设置为:1447 - 1 = 1446,当前1447发送失败的包(TCP payload 1395)会被拆成原来探测成功的mtu 1394大小的两个包1408(tcp payload 1342)、119(tcp payload 53),等待进入下一次向下MTU探测。
但这一次发出的1447的探测包由于中间路由机的MTU只有1430所以被丢弃了,因此会触发tcp_mtup_probe_failed的探测失败逻辑,探测的search_high被设置为:1447 - 1 = 1446,当前1447发送失败的包(TCP payload 1395)会被拆成原来探测成功的mtu 1394大小的两个包1408(tcp payload 1342)、119(tcp payload 53),等待进入下一次向下MTU探测。 - 当下一次通过tcp_write_xmit发送数据触发tcp_mtu_probe的时候,如果各项探测逻辑如果满足,继续进行MTU探测,此时search_low=1394,search_high=1446,本次向下探测的MTU为: (1394 + 1446) / 2 = 1420。该探测包发出后被成功ACK确认,MSS被提升到1368,如下:
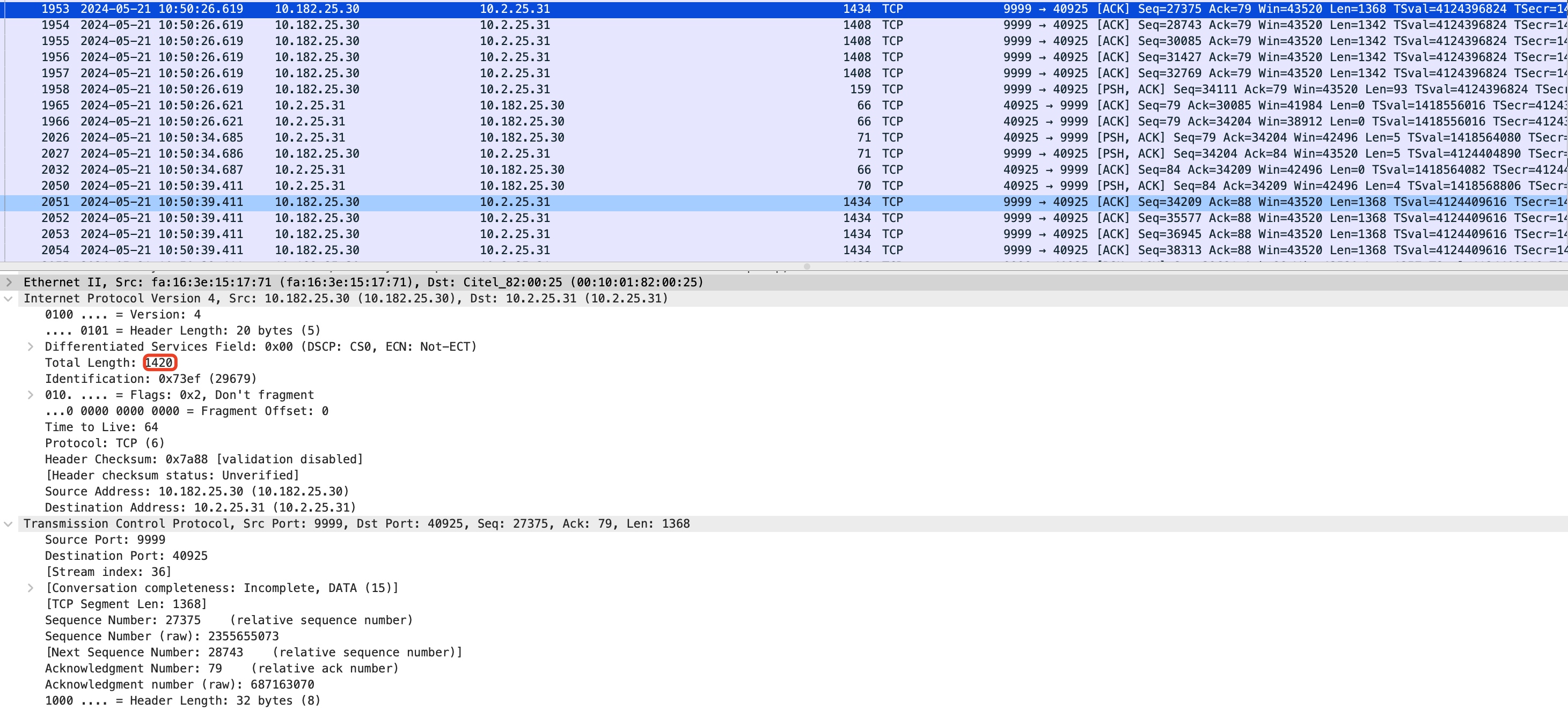
- 继续向上探测mtu,探测的search_low被设置为1420,search_high=1446,下一次向上探测的MTU为: (1420 + 1446) / 2 = 1433,但是该包显然也无法通过路由机,发送失败后,继续触发向下探测。
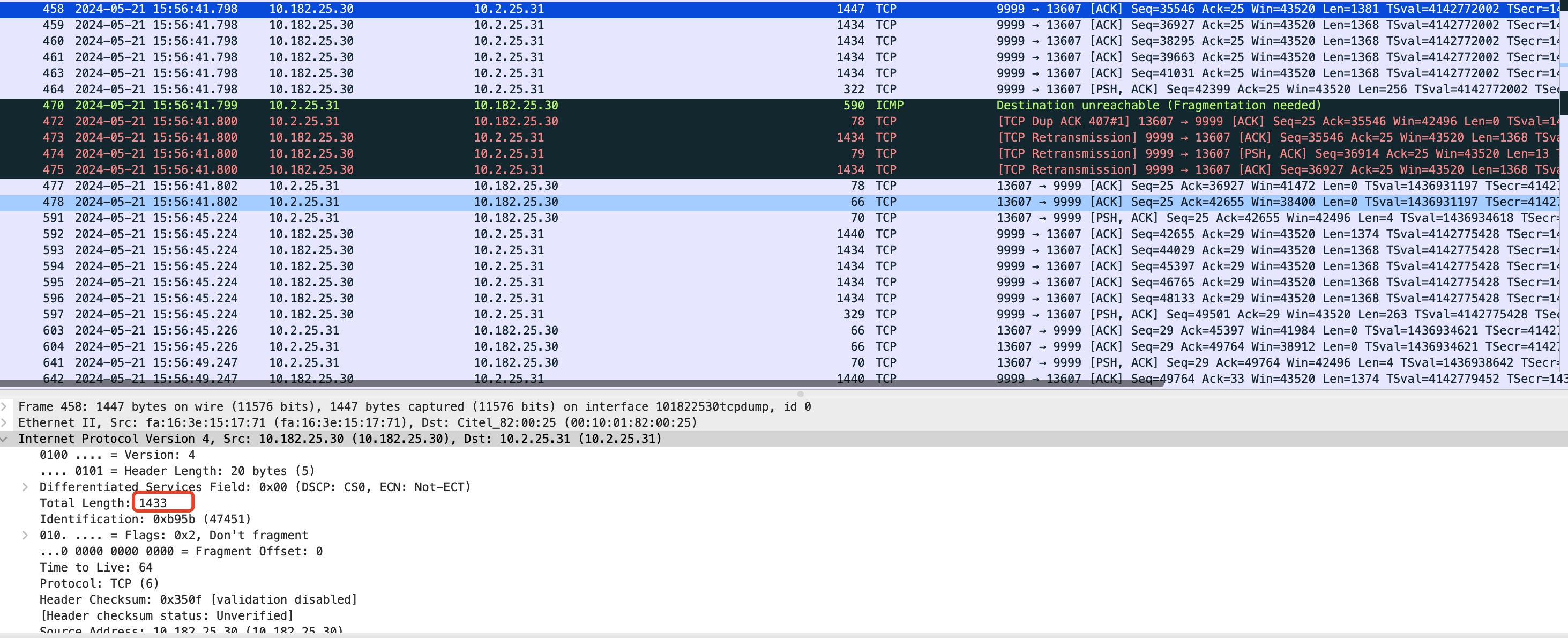
- 1433失败后继续向下探测,search_low=1420,search_high=1433 - 1 = 1432 ,探测的MTU为 (1432 + 1420) / 2 = 1426,此次探测包被成功ACK。
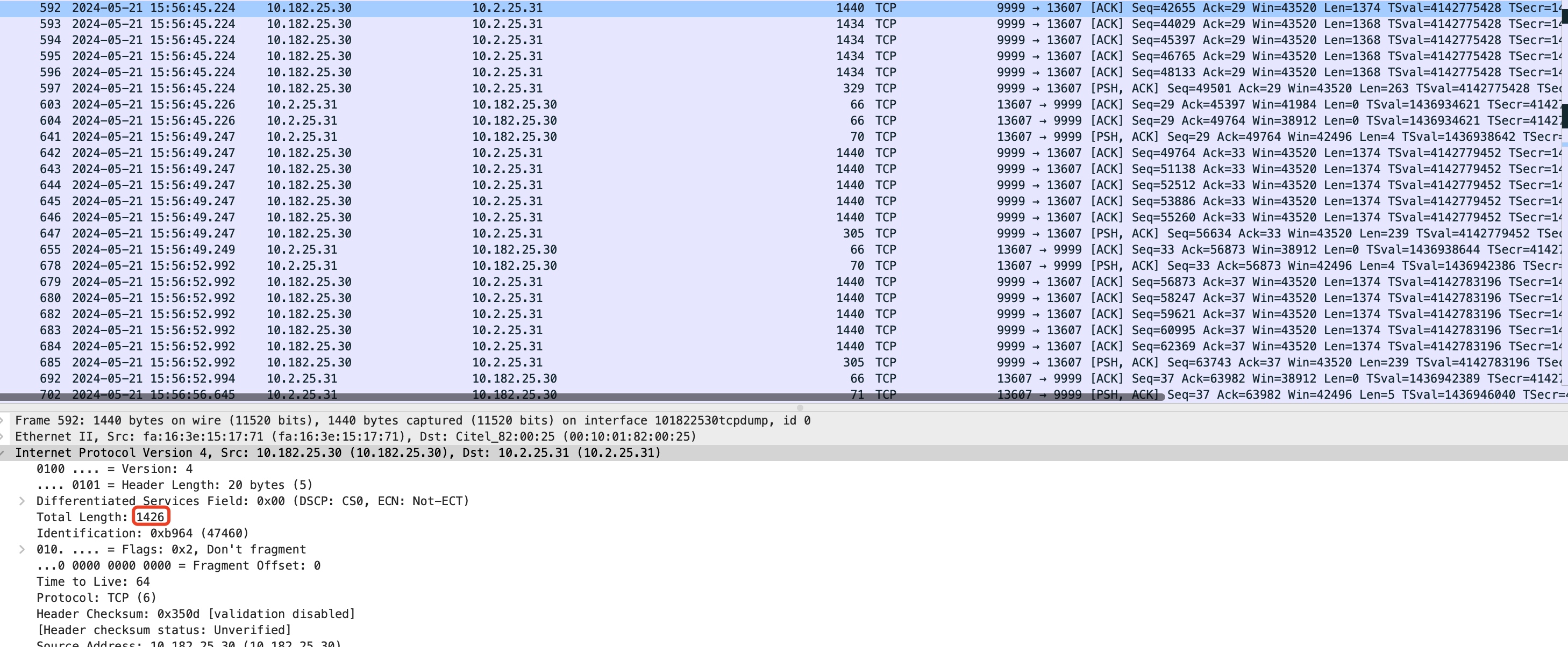 此时,search_low被提升至1426,search_high仍然是1432,由于 1432 - 1426 = 6,已经小于net.ipv4.tcp_probe_threshold的探测默认允许的差异值8,因此后面不再进行常规探测,在net.ipv4.tcp_probe_interval 10分钟后会触发一次reprobe,但基本上也没啥用了,所以最终该连接的MTU被锁定在1426。
此时,search_low被提升至1426,search_high仍然是1432,由于 1432 - 1426 = 6,已经小于net.ipv4.tcp_probe_threshold的探测默认允许的差异值8,因此后面不再进行常规探测,在net.ipv4.tcp_probe_interval 10分钟后会触发一次reprobe,但基本上也没啥用了,所以最终该连接的MTU被锁定在1426。 - 注意最后清理iptables的这些临时加的规则:
sudo iptables -t nat -D PREROUTING 1 sudo iptables -t nat -D POSTROUTING 2 sudo iptables -D INPUT 1
PLPMTUD - QUIC的MTU探测
由于UDP协议没有类似TCP协议在握手期间的MSS协商机制,不能进行MSS clamping,也没有内核自带的PLPMTUD(tcp_mtu_probing),因此需要通过MTU探测才能获取整个链路的PMTU,然后进行提前拆包,避免发出超过PMTU大小的包在IP层被分片影响传输效率和处理性能。从抓包和nginx的pmtud代码来看,chrome浏览器和cronet网络库的初始发包大小是1250,nginx的初始发包大小是1200,nginx每隔100ms进行pmtud探测,探测包使用PING frame和PADDING frame承载,先从1500开始,采用二分查找法,不断寻找pmtu的上限,直到当前确定可用的mtu和之前探测的不可用mtu的最小值的差距小于16的时候就停止。

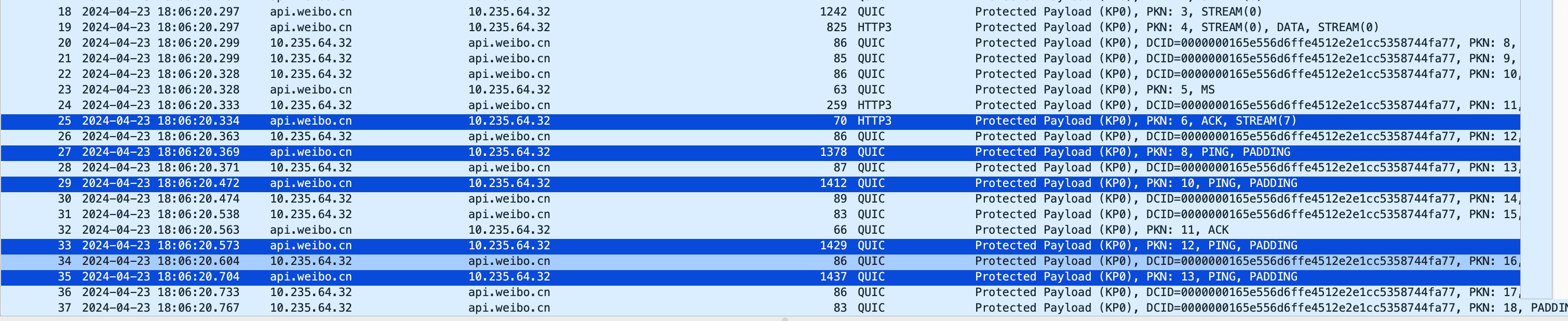
如图示例,我强制将服务端mtu设置为1430,nginx的pmtud从1200大小发quic包(对应mtu是1200+20(ip头)+8(udp头)=1228,加上14bytes的Ethernet II长度,wireshark显示length为1242),然后直接尝试1500的mtu上限,由于服务端mtu被调整为1430所以会直接失败,可以发现PKN 6之后少了PKN 7的包,实际上就是1500的发包失败导致的(我这里是在服务端抓的包,如果是链路上的pmtu小于1500,而不是因为我特意调整的服务端的mtu,那么这里应该能抓到服务端发出的1500的探测包)。 1500的探测包发出失败后,采用二分法进行下探,下一次探测包的mtu就是(1200+1500)/ 2 = 1364,对应抓包显示的就是length为1378的探测包,探测成功收到这个探测包的ack后继续往上探,100ms后下一次探测包的mtu大小为(1364+1500) / 2 = 1432,但由于服务器mtu只有1430,所以这一次探测的发包也失败了(可以看到缺了一个PKN 9的包),探测失败后继续下探,100ms后下一次探测包的mtu就是 (1364+1432)/ 2 = 1398(抓包length显示为1412),成功后继续上探,100ms后下一次探测包的mtu就是 (1398+1432)/ 2 = 1415(抓包length显示为1429),成功后继续上探,100ms后下一次探测包的mtu就是 (1415+1432)/ 2 = 1423(抓包length显示为1437),由于当前已探测到的最小的不可打达的mtu上限为1432,1432-1423=9,已经小于16的精度值了,后续就不再继续探测了。
对应的nginx的代码:
nginx/src/event/quic
/ngx_event_quic.h
#define NGX_QUIC_MIN_INITIAL_SIZE 1200
nginx/src/event/quic
/ngx_event_quic_migration.c
#define NGX_QUIC_PATH_MTU_DELAY 100
#define NGX_QUIC_PATH_MTU_PRECISION 16
void
ngx_quic_discover_path_mtu(ngx_connection_t *c, ngx_quic_path_t *path)
{
ngx_quic_connection_t *qc;
qc = ngx_quic_get_connection(c);
if (path->max_mtu) {
if (path->max_mtu - path->mtu <= NGX_QUIC_PATH_MTU_PRECISION) {
path->state = NGX_QUIC_PATH_IDLE;
ngx_quic_set_path_timer(c);
return;
}
path->mtud = (path->mtu + path->max_mtu) / 2;
} else {
path->mtud = path->mtu * 2;
if (path->mtud >= qc->ctp.max_udp_payload_size) {
path->mtud = qc->ctp.max_udp_payload_size;
path->max_mtu = qc->ctp.max_udp_payload_size;
}
}
path->state = NGX_QUIC_PATH_WAITING;
path->expires = ngx_current_msec + NGX_QUIC_PATH_MTU_DELAY;
ngx_log_debug2(NGX_LOG_DEBUG_EVENT, c->log, 0,
"quic path seq:%uL schedule mtu:%uz",
path->seqnum, path->mtud);
ngx_quic_set_path_timer(c);
}
可以看到,nginx的实现中,QUIC的PLPMTUD机制和内核的tcp_mtu_probing类似,从1200开始往上采用binary search的方式每隔100ms来探测PMTU,直到收敛到16的精度内才会停止,不一样的地方是QUIC的探测是采用的是PING frame + 补PADDING包的方式来实现的,不会使用应用层的数据,相对也会更安全一些。
参考
https://redwingz.blog.csdn.net/article/details/89163458
https://cloud.tencent.com/developer/article/1411872
https://zhuanlan.zhihu.com/p/607408043
https://blog.csdn.net/dog250/article/details/88820733
https://elixir.bootlin.com/linux/v5.14/source/net/ipv4/tcp_timer.c
https://elixir.bootlin.com/linux/v5.14/source/net/ipv4/tcp_input.c
https://elixir.bootlin.com/linux/v5.14/source/net/ipv4/tcp_output.c