最近线上一个服务偶发单机接口耗时飙升的现象,伴随着内存使用增长并出现吃swap的情况,16核的系统load也飙升到50以上,IOUtil接近100%。而且大部分出现问题的机器在接口耗时飙升一段时间后能逐步恢复正常。起初以为是发生了FullGC导致业务线程暂停,通过GC日志查看,出现问题期间GC比较正常,除了有一些类似下图中由于吃swap导致系统整体变慢的GC情况外,堆内本身内存使用并没有啥大问题,内存的增长应该是堆外内存引起的。
2019-12-16T13:21:02.774+0800: 132066.554: [GC (Allocation Failure) 2019-12-16T13:21:02.787+0800: 132066.568: [ParNew
Desired survivor size 214728704 bytes, new threshold 4 (max 4)
- age 1: 116984656 bytes, 116984656 total
- age 2: 44829120 bytes, 161813776 total
- age 3: 33666176 bytes, 195479952 total
- age 4: 23269120 bytes, 218749072 total
: 3568365K->272933K(3774912K), 7.3890574 secs] 5366085K->2111264K(7969216K), 7.9188701 secs] [Times: user=1.24 sys=0.30, real=7.92 secs]
2019-12-16T13:21:10.753+0800: 132075.179: Total time for which application threads were stopped: 8.8991477 seconds, Stopping threads took: 0.0083747 seconds
由于并没有出现FullGC但是整个接口耗时飙升,感觉是线程在哪一块hang住了,于是把出现问题的JVM的线程栈dump下来,拿到线程栈简单按线程状态统计了一下,发现大部分线程被BLOCK住了。
cat jstack.log | awk '/java.lang.Thread.State/ {++state[$0]} END {for(key in state) print key,"\t",state[key]}'
java.lang.Thread.State: WAITING (on object monitor) 5 java.lang.Thread.State: TIMED_WAITING (on object monitor) 85
java.lang.Thread.State: TIMED_WAITING (parking) 1132
java.lang.Thread.State: WAITING (parking) 1100
java.lang.Thread.State: TIMED_WAITING (sleeping) 938
java.lang.Thread.State: BLOCKED (on object monitor) 3409
java.lang.Thread.State: RUNNABLE 174
进一步排查被BLOCK的的线程,发现基本上都是在等一个锁(- waiting to lock <0x00000006c0001128> (a org.apache.catalina.loader.WebappClassLoader)。
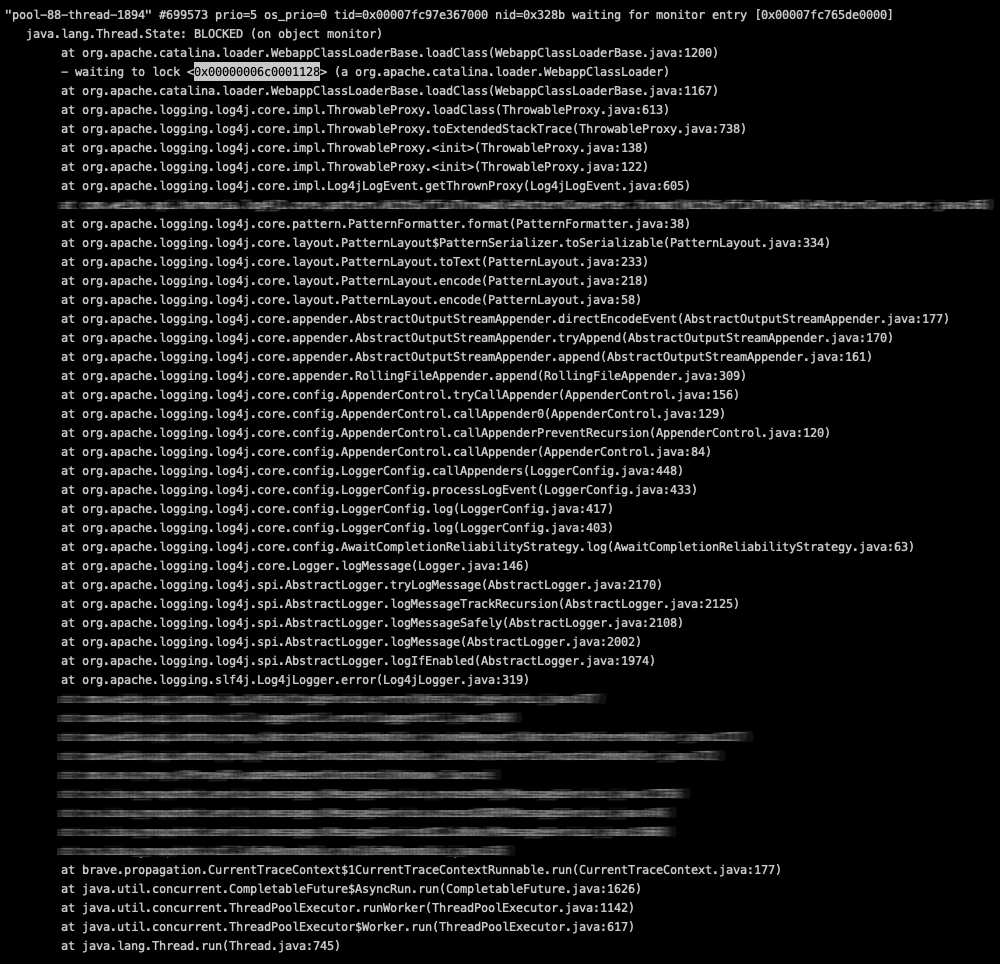
再查下这个锁被另一个线程所持有,从线程栈看,当前这个线程当前状态是在进行类加载从而读取jar包,从线程调用栈看应该是log4j在打印异常日志时触发了类加载。
这里的有几个问题:
- log4j打印异常日志为什么需要进行类加载?
- 为什么这个地方会导致其他线程被block?
log4j打印异常栈过程分析
带着上面的疑问,我们从源码维度来分析下log4j打印异常栈的全过程,搞清楚打印异常栈日志和类加载的关系。
ThrowableProxy的用途
顺着源码查了一下,原来log4j在打印异常日志的时候,默认会把异常栈中每一个涉及到的类的代码行、所在包名、包的版本这些信息都打印出来,目的是方便用户通过异常栈的这些信息快速定位问题(异常栈发生在哪些jar包的哪个类的哪一行),因为这些异常栈可能会在多个JVM或者不同的ClassLoader间传递(比如RPC等网络传输)。比如RPC的Server端抛了一个异常,Client端把这个异常对应的异常栈log下来,这个时候有可能这个Server端的异常栈携带的这些包信息啥的在当前Client端的JVM里不能被正确识别:比如Server端传递过来的异常栈上某一个类所在的jar包的版本和jar包名在当前Client端的JVM里不一样,所以在当前Client端的JVM里把这个异常栈打印出来的时候就需要替换成当前JVM里的这个类所在的jar包名和版本。
比如下面的示例,RPC的client端调用Server端时,Server端抛出了异常,但是由于Server异常栈里依赖的guava版本是18.0,而Client的依赖里只有guava的21.0版本,所以这里在Client端的展示上就会显示成21.0的本地依赖版本(这里注意:虽然这里进行了版本替换,但是出错的代码行并不会进行修正)。
Server端

Client端

log4j在实现上是通过ThrowableProxy这个类来对异常进行包装的。官方API对ThrowableProxy的介绍如下:
Wraps a Throwable to add packaging information about each stack trace element.
A proxy is used to represent a throwable that may not exist in a different class loader or JVM. When an application deserializes a ThrowableProxy, the throwable may not be set, but the throwable's information is preserved in other fields of the proxy like the message and stack trace.
总结下ThrowableProxy对普通异常栈包装的必要性: 为了实现跨ClassLoader和跨JVM对异常栈的正确封装,需要ThrowableProxy能够通过日志事件接收到的普通异常栈信息,从当前上下文的ClassLoader尝试获取“本地”正确的堆栈里的类所属的jar包和版本等信息,便于用户排查问题。
生成“携带正确类属性”的扩展堆栈信息生成逻辑代码如下,log4j2新版本这一块的逻辑在ThrowableProxyHelper类的toExtendedStackTrace方法里。如下:
ThrowableProxy(final Throwable throwable, final Set<Throwable> visited) {
this.throwable = throwable;
this.name = throwable.getClass().getName();
this.message = throwable.getMessage();
this.localizedMessage = throwable.getLocalizedMessage();
final Map<String, ThrowableProxyHelper.CacheEntry> map = new HashMap<>();
final Stack<Class<?>> stack = StackLocatorUtil.getCurrentStackTrace();
this.extendedStackTrace = ThrowableProxyHelper.toExtendedStackTrace(this, stack, map, null, throwable.getStackTrace());
final Throwable throwableCause = throwable.getCause();
final Set<Throwable> causeVisited = new HashSet<>(1);
this.causeProxy = throwableCause == null ? null : new ThrowableProxy(throwable, stack, map, throwableCause,
visited, causeVisited);
this.suppressedProxies = ThrowableProxyHelper.toSuppressedProxies(throwable, visited);
}
下面是生成扩展异常栈信息的具体实现:
/**
* Resolve all the stack entries in this stack trace that are not common with the parent.
*
* @param src Instance for which to build an extended stack trace.
* @param stack The callers Class stack.
* @param map The cache of CacheEntry objects.
* @param rootTrace The first stack trace resolve or null.
* @param stackTrace The stack trace being resolved.
* @return The StackTracePackageElement array.
*/
static ExtendedStackTraceElement[] toExtendedStackTrace(
final ThrowableProxy src,
final Stack<Class<?>> stack, final Map<String, CacheEntry> map,
final StackTraceElement[] rootTrace,
final StackTraceElement[] stackTrace) {
int stackLength;
if (rootTrace != null) {
int rootIndex = rootTrace.length - 1;
int stackIndex = stackTrace.length - 1;
while (rootIndex >= 0 && stackIndex >= 0 && rootTrace[rootIndex].equals(stackTrace[stackIndex])) {
--rootIndex;
--stackIndex;
}
src.setCommonElementCount(stackTrace.length - 1 - stackIndex);
stackLength = stackIndex + 1;
} else {
src.setCommonElementCount(0);
stackLength = stackTrace.length;
}
final ExtendedStackTraceElement[] extStackTrace = new ExtendedStackTraceElement[stackLength];
Class<?> clazz = stack.isEmpty() ? null : stack.peek();
ClassLoader lastLoader = null;
for (int i = stackLength - 1; i >= 0; --i) {
final StackTraceElement stackTraceElement = stackTrace[i];
final String className = stackTraceElement.getClassName();
// The stack returned from getCurrentStack may be missing entries for java.lang.reflect.Method.invoke()
// and its implementation. The Throwable might also contain stack entries that are no longer
// present as those methods have returned.
ExtendedClassInfo extClassInfo;
if (clazz != null && className.equals(clazz.getName())) {
final CacheEntry entry = toCacheEntry(clazz, true);
extClassInfo = entry.element;
lastLoader = entry.loader;
stack.pop();
clazz = stack.isEmpty() ? null : stack.peek();
} else {
final CacheEntry cacheEntry = map.get(className);
if (cacheEntry != null) {
final CacheEntry entry = cacheEntry;
extClassInfo = entry.element;
if (entry.loader != null) {
lastLoader = entry.loader;
}
} else {
final CacheEntry entry = toCacheEntry(ThrowableProxyHelper.loadClass(lastLoader, className), false);
extClassInfo = entry.element;
map.put(className, entry);
if (entry.loader != null) {
lastLoader = entry.loader;
}
}
}
extStackTrace[i] = new ExtendedStackTraceElement(stackTraceElement, extClassInfo);
}
return extStackTrace;
}
这里log4j2的实现里rootTrace默认是null,所以这个方法的核心逻辑就是把普通的堆栈元素封装成携带扩展类信息(ExtendedClassInfo)的异常栈元素对象。主要是以下3步:
-
先判断异常栈(stackTrace)里的类名和当前运行代码的调用堆栈(stack)类名是否相同,如果相同就直接通过当前运行堆栈的类信息来获取“类扩展信息”并添加到缓存里,同时设置lastLoader为当前代码调用栈类所使用的ClassLoader;
-
如果异常栈里的类名和当前运行代码的调用堆栈类名不同,那么先从缓存中获取异常栈“类扩展信息”,获取到的话还会同步更新lastLoader为缓存的ClassLoader;
-
如果缓存miss,会使用lastLoader按照异常栈上的类名来进行类加载,并获取”扩展类信息“,如果获取不到则使用”?“来代替。
由前面jstack下来的业务线程栈持有锁的堆栈信息可以判断,当前持有锁的线程应该是走到了第3步,也就是进入”类加载“的步骤中。类加载的关键代码是:
ThrowableProxyHelper.loadClass(lastLoader, className)
顺便提一下: 针对“类扩展信息”,log4j在这里用到了一个“堆栈级”的缓存,用来缓存当前堆栈解析时已经获取到的“类扩展信息”。这里没有启用一个全局的缓存应该主要还是考虑在同一个JVM会存在多个不同版本信息的类存在,比如OSGi服务中会存在同一个JVM存在多个不同版本类的情况。所以,暂时log4j“类扩展信息”的缓存只限于同一个堆栈中相同的类重复出现时有用,具体是否采用全局缓存的讨论见(这里)。
另外, 更悲催的是: 低版本的log4j这个缓存的实现还有bug,缓存map在put和get时用的key还不一样,所以根本也没法命中,具体的issue在(这里),这个问题微博的一位同事提交了相应的bug fix,已经merge到新版本上了(2.11.1+)。
好了,往回收一下,不再做其他无关的内容延伸,我们继续来看log4j加载类的具体实现:
/**
* Loads classes not located via Reflection.getCallerClass.
*
* @param lastLoader The ClassLoader that loaded the Class that called this Class.
* @param className The name of the Class.
* @return The Class object for the Class or null if it could not be located.
*/
private static Class<?> loadClass(final ClassLoader lastLoader, final String className) {
// XXX: this is overly complicated
Class<?> clazz;
if (lastLoader != null) {
try {
clazz = lastLoader.loadClass(className);
if (clazz != null) {
return clazz;
}
} catch (final Throwable ignore) {
// Ignore exception.
}
}
try {
clazz = LoaderUtil.loadClass(className);
} catch (final ClassNotFoundException | NoClassDefFoundError e) {
return loadClass(className);
} catch (final SecurityException e) {
return null;
}
return clazz;
}
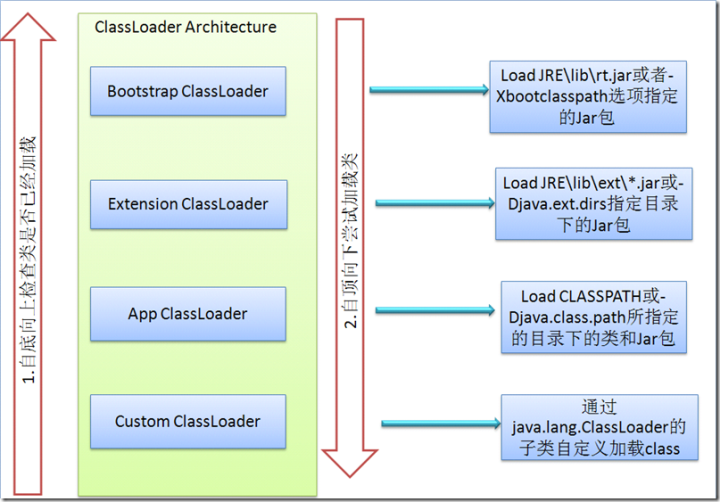
这一步就是真正的通过类名来加载类的过程了。先尝试通过传入的lastLoader来尝试进行类加载,这里的lastLoader就是上一次成功加载到了异常栈中上一行的类名的类所使用的ClassLoader。lastLoader.loadClass的整个类加载过程就是按照标准的”双亲委托“模式来进行: 比如sun.misc.Launcher$AppClassLoader ->(委托给) sun.misc.Launcher$ExtClassLoader -> (委托给) BootstrapClassLoader(native实现)。
这里顺便提一下ClassLoader的”双亲委托“模式。使用”双亲委托“模式来进行类加载主要是考虑两个因素:
-
避免类的重复加载,当父加载器已经加载了该类的时候,就没有必要使用当前类加载器再加载一次。
-
安全考虑,避免一些jdk的系统类被用户重新定义。
贴一张网上流传广泛的ClassLoader的体系架构图:
如果lastLoader通过“双亲委托”方式没有成功加载到这个类,那么会继续通过 LoaderUtil.loadClass(className) 来再次尝试,LoaderUtil.loadClass加载类的实现如下:
public static Class<?> loadClass(final String className) throws ClassNotFoundException {
if (isIgnoreTccl()) {
return Class.forName(className);
}
try {
return getThreadContextClassLoader().loadClass(className);
} catch (final Throwable ignored) {
return Class.forName(className);
}
}
在这一步:先使用当前执行线程使用的ClassLoader来尝试加载所需的类,如果还是没有加载到,那么会通过Class.forName来尝试进行类加载。
如果仍然没有加载到所需的类,通过ThrowableProxyHelper类的loadClass方法,log4j还会使用当前ThrowableProxyHelper类所属的ClassLoader来进行最后的尝试。代码如下:
private static Class<?> loadClass(final String className) {
try {
return Loader.loadClass(className, ThrowableProxyHelper.class.getClassLoader());
} catch (final ClassNotFoundException | NoClassDefFoundError | SecurityException e) {
return null;
}
}
如果这一步仍然失败,那么最终就会catch住异常,返回null。如果返回null,那么最终这些”扩展类信息“会使用”?“来占位打印。
通过对以上3步的分析,log4j针对异常栈中类的加载流程基本理清了,我们再根据当时jstack下来的持有锁的线程的线程栈信息来进一步分析,长时间hang住的地方是在ClassLoader类的这个同步锁synchronized (getClassLoadingLock(name)) 这里,而且同步块中当前正在进行jar包读取。

对应的锁的位置在抽象类ClassLoader里对应的源码如下:
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
由于loadClass这一步会先通过findLoadedClass来从当前ClassLoader已加载的类中查找目标类,只有找不到的情况才会通过findClass来尝试从jar包中读取类信息。 比如Tomcat的类加载器WebappClassLoader在自定义的findClass方法里,会通过 findClassInternal -> resources.getClassLoaderResource这些调用路径来搜寻classpath下的jar包查找目标类,上面jstack下来的持有锁的线程当前正是tomcat的WebappClassLoader在读取jar包。 具体这一块的源码就不贴了,有兴趣的可以看:这里
从log4j针对异常栈中类的加载流程来看,对于没有被加载过的目标类,会通过findClass来尝试从classpath下的jar包和.class文件来进行加载,经过”双亲委托“和”自定义ClassLoader“各自的jar包路径查找,整个查找过程是很长而且比较慢的,如果这个时候同时有其它线程需要进行类加载,那么就会被全局的ClassLoader类的同步锁block住,如果这种”需要读取jar包获取类信息“的情况并发较高,就会导致大部分并发请求都被block,从而拖慢业务线程。
这里不难得出,如果是JVM刚启动的时候,由于JVM对类的“lazy load”机制,是比较容易出现很多类出现同时需要“通过jar包加载类”来完成加载的情况,会出现由于同步锁拖慢业务线程的情况。但是从线上出现问题的时间点来看,实际上出问题时并不是JVM刚启动,而是比较随机的出现在运行一段时间后,理论上这个时候该加载的类应该都已经加载完了,不应该出现大量类miss了findLoadedClass而需要“通过jar包加载”的情况。而且,同一个JVM多次jstack抓下来的线程栈看,这个锁被不同的线程所持有,但当时log4j打印出来的对应的业务异常栈却基本都是一样的。也就是说:log4j打印的这些重复的异常栈所涉及的类里,存在”第一次从jar包加载完,第二次又需要重新从jar包来加载“的情况。如下图:
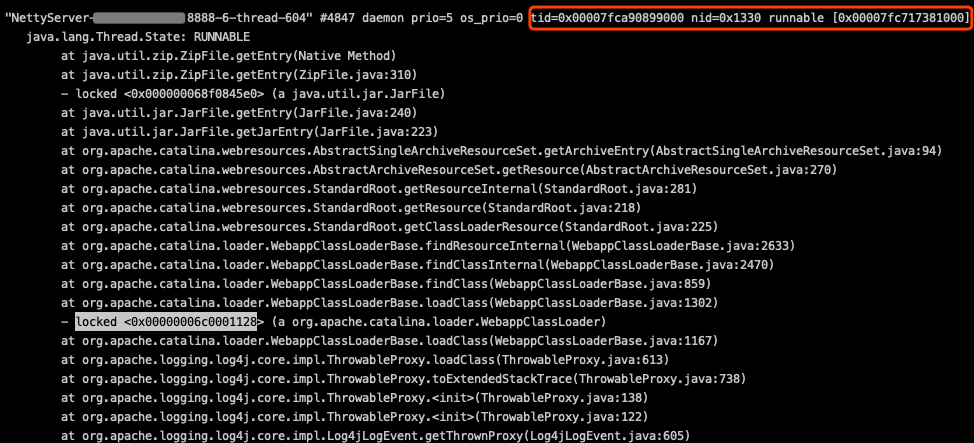
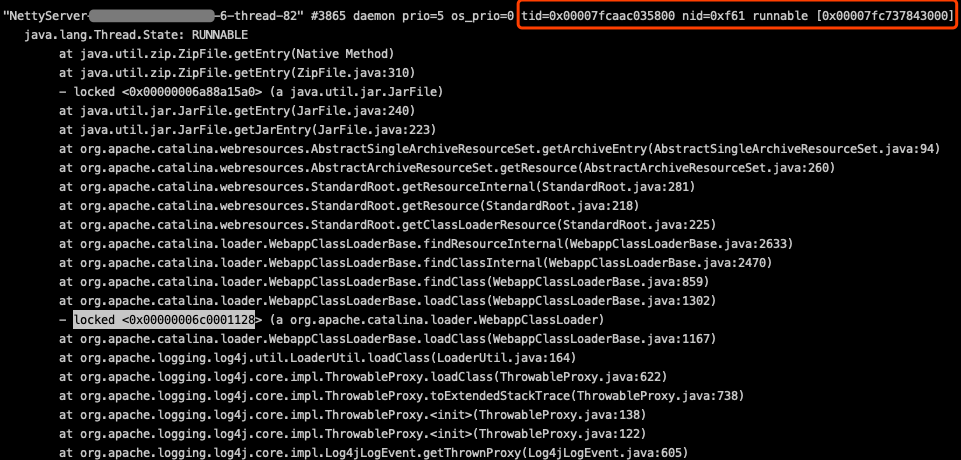
这两次抓到的线程栈都是在从jar包获取类信息,但当时log4j打印的业务异常栈刷的错误日志基本都是同样的异常栈信息。
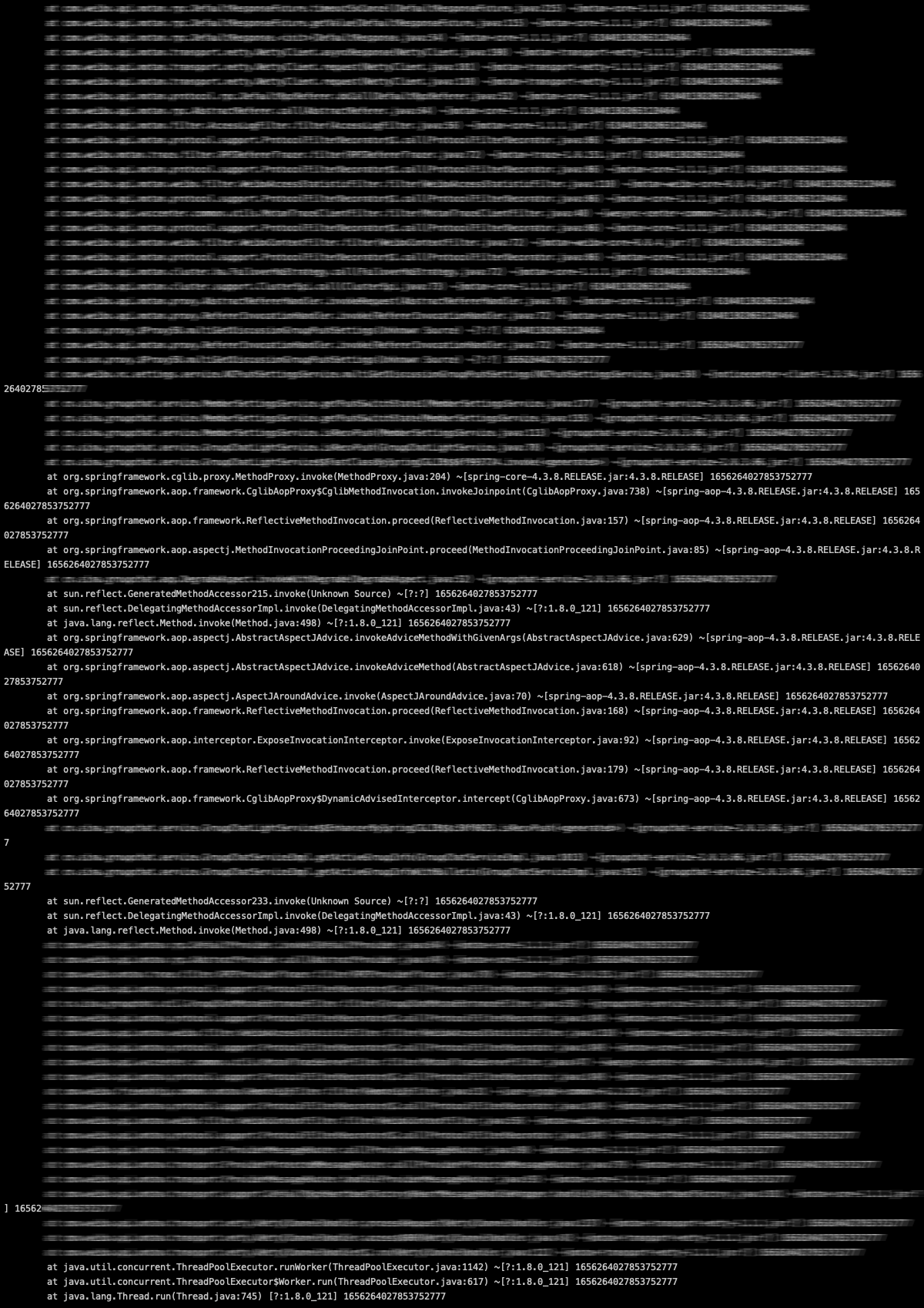
再仔细分析下这个log4j打印的异常栈,发现其中存在两个比较奇怪的类:sun.reflect.GeneratedMethodAccessor233和sun.reflect.GeneratedMethodAccessor215,从包命名和类命名上来,这两个类应该是java反射自动生成的类。 针对性的了解了一下这两个类,实际上在JDK源码中并不存在这两个类,这两个类是JVM运行态在反射调用时自动生成的类。
java反射机制
接下来了解下java的反射机制,java反射机制是比较常见的特性,反射能够在编译器不强依赖具体类,而是在运行时动态获取类的实例,从而进行实例方法调用等进一步操作,我们日常开发中常用的spring等框架就是通过反射机制,来将xml中配置的bean真正实例化成对象。
JVM内部对于反射的实现有两种方式:
-
JNI:使用native方法进行反射操作,使用sun.reflect.NativeMethodAccessorImpl.invoke0本地方式。
-
Java动态类:通过java动态生成类sun.reflect.GeneratedMethodAccessor,通过这个包装类的invoke方法来执行最终调用的方法。(这里GeneratedMethodAccessor碰到多线程并发生成的情况会自增)。
按照R大的说法(这里),native的反射实现在开始时会比Java动态类的实现性能好,但运行一段时间后,Java动态类的实现由于内联优化比native的反倒更快一些:
Java实现的版本在初始化时需要较多时间,但长久来说性能较好;native版本正好相反,启动时相对较快,但运行时间长了之后速度就比不过Java版了。这是HotSpot的优化方式带来的性能特性,同时也是许多虚拟机的共同点:跨越native边界会对优化有阻碍作用,它就像个黑箱一样让虚拟机难以分析也将其内联,于是运行时间长了之后反而是托管版本的代码更快些。 为了权衡两个版本的性能,Sun的JDK使用了“inflation”的技巧:让Java方法在被反射调用时,开头若干次使用native版,等反射调用次数超过阈值时则生成一个专用的MethodAccessor实现类,生成其中的invoke()方法的字节码,以后对该Java方法的反射调用就会使用Java版。
JVM有两个参数来控制这种优化:
- -Dsun.reflect.inflationThreshold=N 默认为15次,即反射调用某个方法15次后,会由JNI的native方式变为java动态类的方式。
- -Dsun.reflect.noInflation=true 默认为false。当设置为true时,表示在第一次反射调用时,就转为java动态类的方式。
最小化重现问题和验证
收回到我们问题排查的思路上,我们了解了线程栈中这两个异常类是由于java的反射动态生成,为了验证确实是由于这两个类导致的类加载问题,可以通过反射调用来最小化的代码验证一下:
TestReflectionClassLoad主程序,通过反射调用TestCallee的sayHello方法,然后故意传递一个错误参数到sayHello方法, 让它抛出异常,然后通过log4j2记录这个异常。
import java.lang.reflect.Method;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import com.google.common.collect.Lists;
public class TestReflectionClassLoad {
public static void main(String[] args) throws Exception {
ExecutorService es = Executors.newFixedThreadPool(1);
List<Callable<String>> tasks = Lists.newArrayList();
for (int i = 0; i < 2; i++) {
tasks.add(new Task(i + ""));
}
long start = System.currentTimeMillis();
es.invokeAll(tasks);
long end = System.currentTimeMillis();
System.out.println("===========total cost:" + (end - start));
Thread.sleep(1000000000);
}
}
class Task implements Callable<String> {
private final static Logger log = LoggerFactory.getLogger("logfile");
private String name;
public Task(String name) {
this.name = name;
}
@Override
public String call() {
try {
Class<?> clz = Class.forName("TestCallee");
final Object o = clz.newInstance();
final Method m = clz.getMethod("sayHello", String.class);
return (String) m.invoke(o, null);
} catch (Exception e) {
log.error("something bad happened! =====" + name, e);
}
return null;
}
}
被反射调用的测试类TestCallee。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class TestCallee {
protected final static Logger log = LoggerFactory.getLogger("logfile");
public String sayHello(String name) {
String[] names = name.split(":");
return names[0];
}
}
log4j2的配置:
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="info" name="groupchat-service">
<Properties>
<Property name="log-path">logs</Property>
<Property name="log-file-sizelimit">1GB</Property>
</Properties>
<Appenders>
<RollingFile name="logfile" fileName="${log-path}/logfile.log"
filePattern="${log-path}/logfile.log.%d{yyyyMMdd-HH}">
<PatternLayout>
<Pattern>%level{length=1} %d{HH:mm:ss SSS} [%p] %c{1} %m %n</Pattern>
</PatternLayout>
<Policies>
<TimeBasedTriggeringPolicy interval="1" modulate="true"/>
</Policies>
</RollingFile>
</Appenders>
<Loggers>
<ROOT level="info">
<appender-ref ref="logfile" level="info"/>
</ROOT>
</Loggers>
</Configuration>
运行TestReflectionClassLoad类,并通过参数-Dsun.reflect.noInflation=true来强制使用java动态类方式的反射。发现,确实只有GeneratedMethodAccessor这个动态类不管log4j使用哪个ClassLoader都没有办法加载到,导致每次碰到这个类都需要遍历所有的classpath下的jar包来进行搜索,而且每次都还是空手而归。其他类在第一次加载完成后,后续都能通过findLoadedClass从已加载的ClassLoader中快速再加载到。

压测验证
为了验证下线程block和接口耗时飙升确实是由于这个动态类多次加载导致的,我们来简单进行一下压测。
-
调整调用任务个数,从2调整为100000,同时将执行任务的线程数从1调整为10,再调整-Dsun.reflect.inflationThreshold=2147483647,通过这种方式来强制使用本地native方式来进行反射调用,所有任务执行完成的时间为total cost:5350,大概5秒多;
-
调整调用任务个数,从2调整为100000,同时将执行任务的线程数从1调整为10,再使用JVM默认的反射策略(先执行15次native反射后再切换成java动态类方式),所有任务执行完成的时间为total cost:120786,超过了120秒;
-
调整log4j2的配置,放弃在打印异常栈时打印”扩展的类信息“,这样就不需要进行类加载去获取这些扩展信息了(配置里需要通过”%ex“显式指定使用普通堆栈打印,否则默认会打印扩展异常栈信息)。这里需要注意的是:不打印”扩展异常栈信息“可能会降低问题排查效率,毕竟可用的jar包路径、jar包版本这些辅助信息少了很多。除了调整log4j2的配置,类似的,我们也调整调用任务个数,从2调整为100000,同时将执行任务的线程数从1调整为10,再使用JVM默认的反射策略(先执行15次native反射后再切换成java动态类方式),total cost:5875,也大概是不到6s;
<Pattern>%level{length=1} %d{HH:mm:ss SSS} [%p] %c{1} %m %ex %n</Pattern>
对比之下2和1、3的性能差距巨大,于是在默认的反射策略过程中进行堆栈抓包,果然和之前线上的线程栈表现一致,其他9个线程都在加载类的过程中被BLOCK住了。
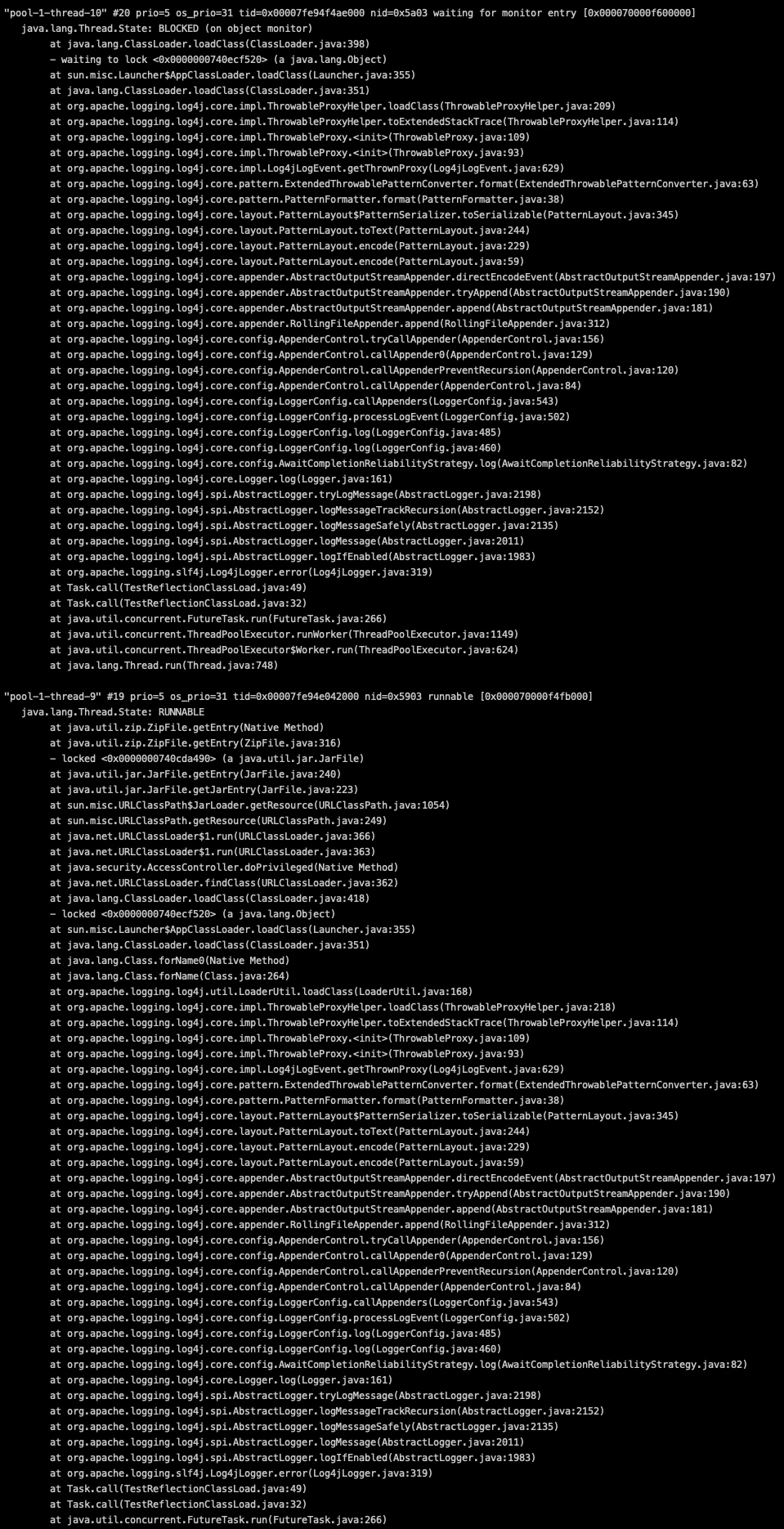
水落石出
到这里基本就结案了,结合业务的异常日志我们分析下原因: 由于我们这个业务首先是作为RPC的Server,对外提供服务,在RPC Server的实现里,RPC框架就是通过反射的方式来invoke具体RPC方法的真实调用;其次在流程中还引用了第三方的熔断组件(Sentinel),通过AOP切面拦截和反射来实现”被保护方法“的熔断和调用。因此整个业务逻辑的调用栈里会多次生成GeneratedMethodAccessor这种动态类,因此当业务异常较多的情况,默认log4j2的”扩展异常栈信息“在加载GeneratedMethodAccessor类的时候,由于需要多个ClassLoader遍历各自负责的classpath下的jar和.class文件来进行搜索,整个搜索的过程会通过一个JVM全局级的锁来进行保护,由于整个搜索过程耗时较长,当这种异常并发较多时,就非常容易出现其他需要打印类似异常栈的业务线程被BLOCK住,从而影响业务接口的整体性能。
延伸思考
那么可能有细心的同学会产生一个新的疑问: 动态生成的GeneratedMethodAccessor类也是由JVM的ClassLoader加载的,为啥log4j却加载不到呢?
要回答这个问题,我们必须得先了解下sun.reflect.GeneratedMethodAccessor类的生成过程,java反射核心的逻辑在“获取到Method后通过invoke来进行调用”,我们主要看下这里的代码:
Method类的invoke方法:
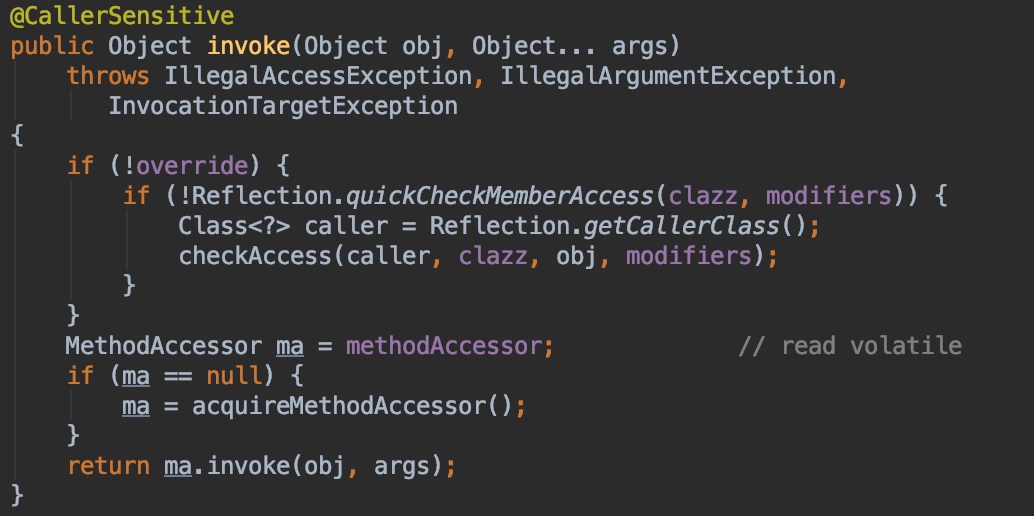
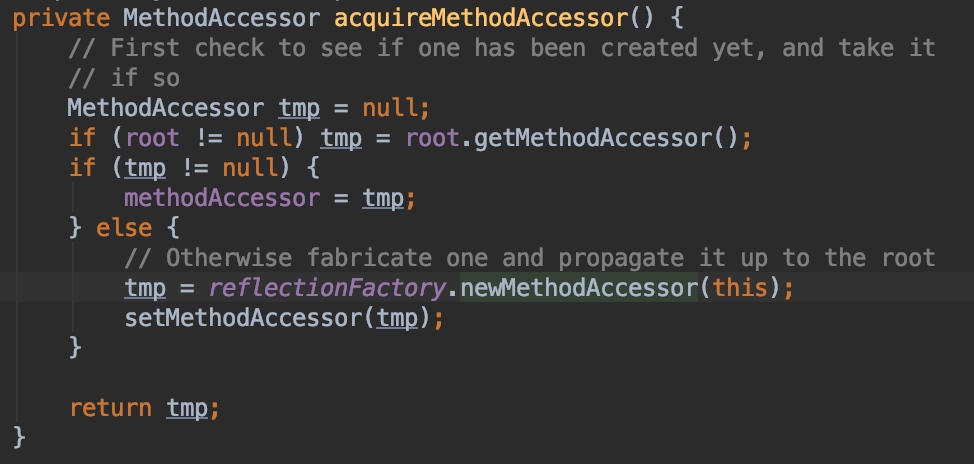
这里主要通过MethodAccessor这个接口的实现类进执行真正的invoke调用,accquireMethodAccessor的主要逻辑是:如果这个Method之前被缓存过,就先从缓存的Method里获取通过MethodAccessor,否则通过会ReflectionFactory来新创建一个MethodAccessor。新创建的核心逻辑代码在这:
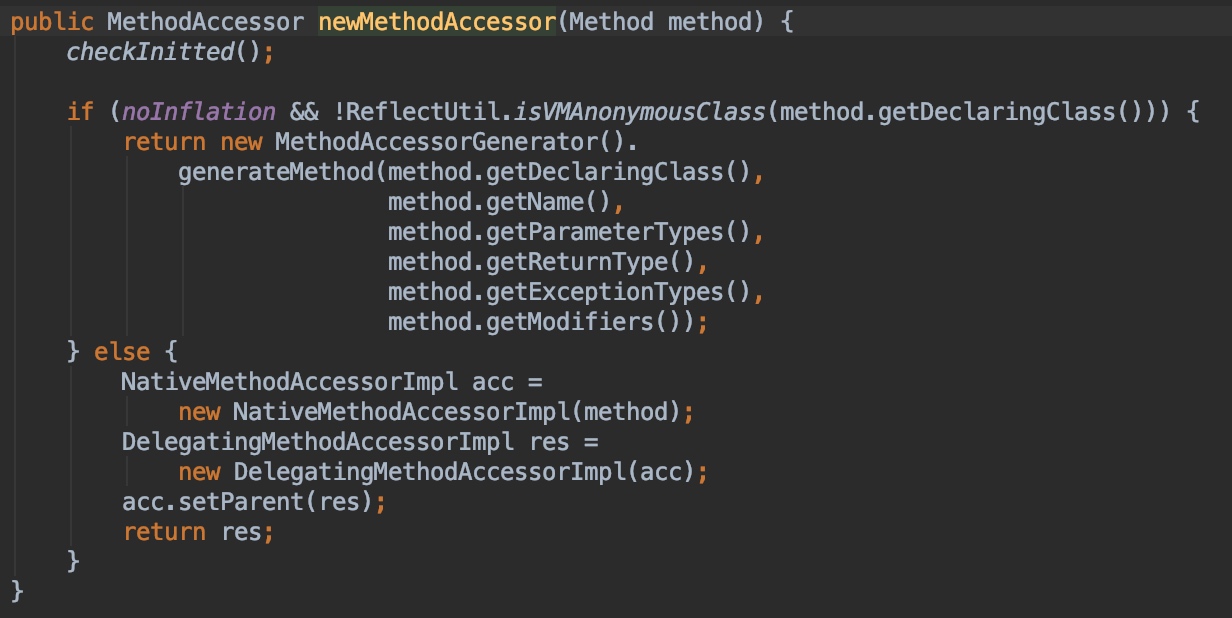
这里的逻辑大概如下: 如果不满足膨胀条件同时当前类不是JDK内部匿名类时,会使用MethodAccessorGenerator来生成MethodAccessor,如果达到inflationThreshold(默认15)的条件、同时noInflation是默认的false,那么在15次之后会封装一个NativeMethodAccessorImpl的MethodAccessor来返回。noInflation(默认false)和inflationThreshold(默认15),这两个设置在checkInitted方法里会读取-Dsun.reflect.inflationThreshold=xxx和-Dsun.reflect.noInflation=true的JVM参数来重新设置。
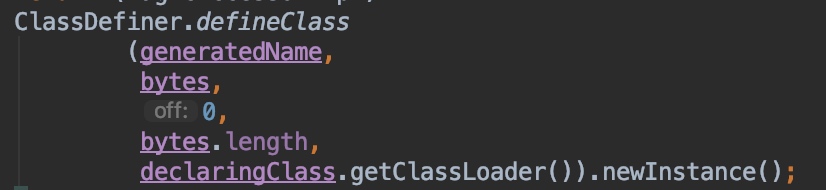
MethodAccessorGenerator.generateMethod方法通过asm字节码工具生成MethodAccessorImpl对象时,会在内存中生成对应类的字节码,并调用ClassDefiner.defineClass创建对应的GeneratedMethodAccessor类。
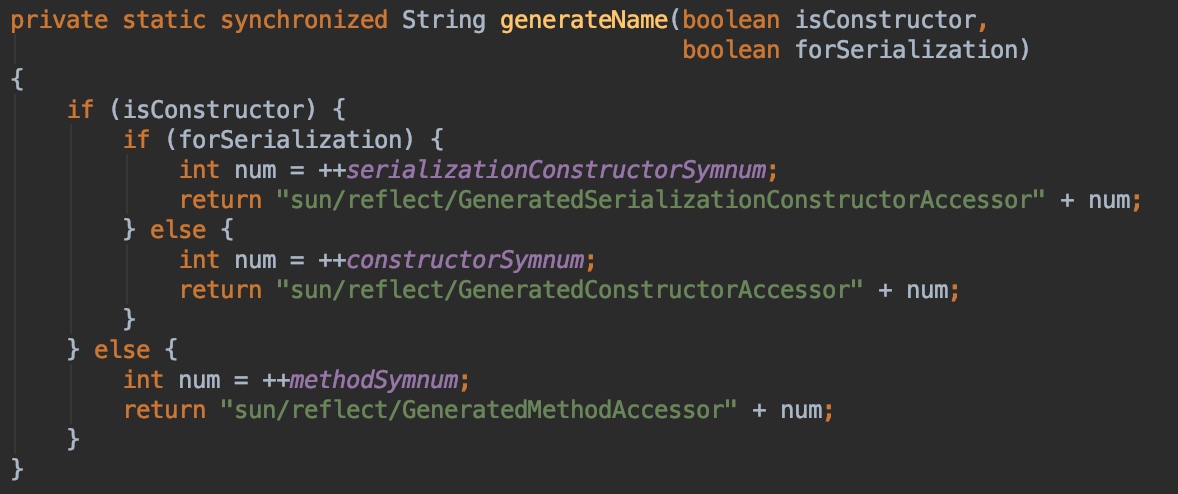
这里的generatedName就是自动生成的GeneratedMethodAccessor的自增类名:
自动生成的这个GeneratedMethodAccessor类是抽象类MethodAccessorImpl的子类,MethodAccessorImpl是MethodAccessor的抽象实现类,GeneratedMethodAccessor实现的invoke方法里就是直接调用目标对象的具体方法。
关键的地方在GeneratedMethodAccessor类的生成定义这里,注意这里用于装载GeneratedMethodAccessor这个类的ClassLoader是用一个新创建的DelegatingClassLoader,见ClassDefiner的defineClass代码:
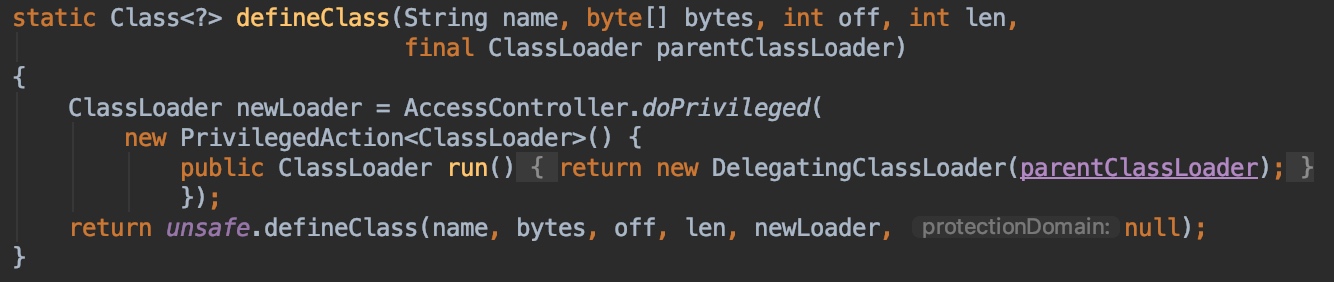
那么为什么每次要用一个新的DelegatingClassLoader来加载生成的动态类呢? 之所以每次生成GeneratedMethodAccessor类都使用一个新的DelegatingClassLoader来装载主要是出于性能考虑,JVM认为这些动态生成的临时类在方法调用结束后并不希望长期在内存中占有系统内存,因此,每次都使用新的ClassLoader来进行装载就能够让这些类能够被卸载掉,因为类的卸载前提是对应的ClassLoader可以被GC回收,如果使用业务应用的ClassLoader来加载,可能会导致这些动态生成的类无法卸载,从而浪费系统内存。而正是由于这个原因,导致log4j通过应用的ClassLoader无法查找到这些动态类,导致需要一次次遍历classpath下的各种jar包和.class文件来进行无用且耗时的遍历。这个也能通过JVM自带的PerfCounter能看出差异。
线上再次验证
一台线上机器通过-Dsun.reflect.inflationThreshold=2147483647来强制使用native方式来使用反射,另一台使用默认参数。运行一段时间后,统计JVM打开zip的总耗时和总zip文件数。分别如下:
jcmd 12 PerfCounter.print
使用native反射方式的PerfCounter数据为:
sun.zip.zipFile.openTime=130382373505(纳秒单位,130s)
sun.zip.zipFiles=162403
使用默认反射方式的PerfCounter数据为:
sun.zip.zipFile.openTime=845682086172(纳秒单位,845s)
sun.zip.zipFiles=6841778
从两个JVM的PerfCounter能看出来:使用默认反射方式的JVM打开的zip文件数和耗费的时间远大于使用native反射方式的JVM,而且使用native反射方式的没有再出现过线程被hang死的情况。
实际上,这个问题在log4j的官方jira里有详细讨论应对方案的issue(这里),不过目前社区里貌似没有完美的办法能够彻底解决这个问题,而且,对于大部分线上业务,由于平时异常不多,也不一定会使用log4j来打印异常栈,而且出问题的前提是还需要异常栈中存在反射生成的动态类,所以一般也比较难出现。
可行的优化方案
对于出现这种情况的业务,目前两个可行的优化策略是:
- 通过-Dsun.reflect.inflationThreshold=2147483647来强制使用native反射方式。这种方式在性能方面会比生成动态类的反射方式会稍微差一些,线上测试验证貌似差距很小。
- 调整log4j的pattern,不打印扩展类信息,这个可以通过显示用“%ex”来配置。因为不存在需要加载类的问题,因此性能基本上是最好的,唯一的缺陷是由于没有类的jar包信息等,问题排查会比较麻烦。
时值“武汉肺炎”肆虐之际,多省市都已成为疫区,而且有愈演愈烈之势,祈祷病情能尽快控制住,武汉加油,中国加油,奥利给!