控制GC日志打印的常用配置项
-XX:+PrintGCDetails
启用详细GC日志模式。和-XX:+PrintGC的普通日志模式相比,详细日志模式会把:使用的垃圾回收器、整个堆在GC前后大小的变化、GC所使用的CPU时间详情(用户空间时间、系统空间时间、真实时间)这些信息都打印出来,相比普通模式会更有用。
- 普通模式
8.227: [GC (Allocation Failure) 5592448K->493816K(19573440K), 0.8932951 secs]
- 详细模式
7.910: [GC (Allocation Failure) 7.911: [ParNew: 5592448K->465929K(6990528K), 0.9267650 secs] 5592448K->465929K(19573440K), 0.9278514 secs] [Times: user=3.63 sys=0.47, real=0.92 secs]
-XX:+PrintGCDateStamps
打印GC的绝对时间,也可以和-XX:+PrintGCTimeStamps(打印JVM启动至今的相对时间)一起启用,方便根据时间点来排查问题。
- 一起使用的效果如下
2018-12-04T15:17:40.560+0800: 7.957: [GC (Allocation Failure) 2018-12-04T15:17:40.561+0800: 7.958: [ParNew: 5592448K->484571K(6990528K), 1.1328709 secs] 5592448K->484571K(19573440K), 1.1335623 secs] [Times: user=3.20 sys=0.42, real=1.14 secs]
-Xloggc
gc日志的具体存放位置,比如可以加上启动时间作为后缀。"-Xloggc:../gclogs/gc.log.date +%Y%m%d_%H%M%S"
-XX:+PrintTenuringDistribution
开启后,会打印出young GC后每个年代的对象分布情况,以及根据”期望的存活区大小“和各年代分布大小计算出的新的提升年代阈值。
- 开启打印年代分布后的效果如下,具体介绍不在这展开,一会找一个案例讲一下。
2018-12-04T15:21:24.245+0800: 26.766: [GC (Allocation Failure) 2018-12-04T15:21:24.245+0800: 26.766: [ParNew
Desired survivor size 715816960 bytes, new threshold 8 (max 8)
- age 1: 289108664 bytes, 289108664 total
- age 2: 35348056 bytes, 324456720 total
- age 3: 17333096 bytes, 341789816 total
: 5747630K->356756K(6990528K), 0.2873193 secs] 5747630K->356756K(19573440K), 0.2877206 secs] [Times: user=3.92 sys=0.03, real=0.29 secs]
-XX:+PrintHeapAtGC
GC前后打印出整个详细使用情况,比如eden区、from区、to区、老年代、Metaspace(方法区)、Class(类元数据)等占用分布情况。
{Heap before GC invocations=7 (full 1):
par new generation total 6990528K, used 6349280K [0x00000002c0000000, 0x00000004c0000000, 0x00000004c0000000)
eden space 5592448K, 99% used [0x00000002c0000000, 0x0000000415559fe0, 0x0000000415560000)
from space 1398080K, 54% used [0x000000046aab0000, 0x0000000498dce300, 0x00000004c0000000)
to space 1398080K, 0% used [0x0000000415560000, 0x0000000415560000, 0x000000046aab0000)
concurrent mark-sweep generation total 12582912K, used 0K [0x00000004c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 82689K, capacity 84535K, committed 84792K, reserved 1124352K
class space used 9162K, capacity 9624K, committed 9720K, reserved 1048576K
2018-12-04T15:27:42.754+0800: 405.276: [GC (Allocation Failure) 2018-12-04T15:27:42.755+0800: 405.276: [ParNew
Desired survivor size 715816960 bytes, new threshold 5 (max 8)
- age 1: 251058512 bytes, 251058512 total
- age 2: 140747848 bytes, 391806360 total
- age 3: 124922464 bytes, 516728824 total
- age 4: 134051104 bytes, 650779928 total
- age 5: 91110512 bytes, 741890440 total
- age 6: 24537776 bytes, 766428216 total
- age 7: 30017936 bytes, 796446152 total
- age 8: 17107928 bytes, 813554080 total
: 6349280K->1090426K(6990528K), 0.1512805 secs] 6349280K->1090426K(19573440K), 0.1520567 secs] [Times: user=2.51 sys=0.55, real=0.15 secs]
Heap after GC invocations=8 (full 1):
par new generation total 6990528K, used 1090426K [0x00000002c0000000, 0x00000004c0000000, 0x00000004c0000000)
eden space 5592448K, 0% used [0x00000002c0000000, 0x00000002c0000000, 0x0000000415560000)
from space 1398080K, 77% used [0x0000000415560000, 0x0000000457e3e868, 0x000000046aab0000)
to space 1398080K, 0% used [0x000000046aab0000, 0x000000046aab0000, 0x00000004c0000000)
concurrent mark-sweep generation total 12582912K, used 0K [0x00000004c0000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 82689K, capacity 84535K, committed 84792K, reserved 1124352K
class space used 9162K, capacity 9624K, committed 9720K, reserved 1048576K
}
-XX:+PrintGCApplicationStoppedTime和-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintGCApplicationStoppedTime 打印所有引起JVM停顿的时间。实际上除了GC会引起JVM的STW外,还有其他操作也会导致JVM的STW,比如JIT、取消偏向锁、线程dump等。-XX:+PrintGCApplicationConcurrentTime会把两次停顿期间业务线程正常运行的时间,这两个一般配合使用。用于发现一些除GC外不明原因的其他停顿。
2018-12-04T15:50:58.170+0800: 115.795: Total time for which application threads were stopped: 0.0880877 seconds, Stopping threads took: 0.0003654 seconds
2018-12-04T15:50:58.172+0800: 115.797: Application time: 0.0019585 seconds
-XX:+PrintSafepointStatistics -XX:PrintSafepointStatisticsCount=1
有的时候会发现,在没有GC的情况下,GC日志中也会有一些其他STW的停顿耗时,类似下面这种并不是由于GC导致的停顿:
2019-02-13T18:00:39.124+0800: 5034188.809: Total time for which application threads were stopped: 0.0026642 seconds, Stopping threads took: 0.0001431 seconds
2019-02-13T18:00:39.126+0800: 5034188.811: Total time for which application threads were stopped: 0.0012837 seconds, Stopping threads took: 0.0000249 seconds
原因是因为GC日志里不仅会把GC导致的暂停打出来,其他操作如:JIT代码优化、取消偏向锁等操作也会导致业务线程暂停,这些暂停也会通过GC日志反馈出来。 会在安全点进行VM操作的行为包括包括:
- Garbage collection pauses
- Code deoptimization
- Flushing code cache
- Class redefinition (e.g. hot swap or instrumentation)
- Biased lock revocation
- Various debug operation (e.g. deadlock check or stacktrace dump)
可以通过以下两个参数把所有导致暂停的具体原因打出来。默认日志打到标准输出流,因此可能有一些不方便,可以配置打到一个专门的日志中(需要开启诊断选项):-XX:+UnlockDiagnosticVMOptions -XX:+LogVMOutput -XX:LogFile=../gclogs/safepoint.log。
具体打印出来的日志示例如下:
125810.273: BulkRevokeBias [ 1820 1 1 ] [ 0 0 0 6 8 ] 0
vmop [threads: total initially_running wait_to_block] [time: spin block sync cleanup vmop] page_trap_count
第一部分125810.273是时间戳,BulkRevokeBias是VM Operation的类型,这里是“批量取消偏向锁”。 第二部分是线程概况,被中括号括起来 total: 安全点里的总线程数1820条 initially_running: 安全点开始时正在运行状态的线程数,这里是1 wait_to_block: 在VM Operation开始前需要等待其暂停的线程数,这里也是1 第三部分是到达安全点时的各个阶段以及执行操作所花的时间,其中最重要的是vmop spin: 等待线程响应safepoint号召的时间; block: 暂停所有线程所用的时间; sync: 等于 spin+block,这是从开始到进入安全点所耗的时间,可用于判断进入安全点耗时; cleanup: 清理所用时间,这里是6ms; vmop: 真正执行VM Operation的时间,这里是8ms;
所以这次“批量取消偏向锁”的VM Operation总共导致了14ms的暂停。
延伸知识点1:安全点(safe point)
什么是安全点?
安全点可以理解为代码中的一些特定位置,当线程运行到这些位置时,它的状态是可以被JVM确定的(对于GC safepoint来说,在每一个安全点上,JVM会生成一些“调试符号信息”,叫OopMap,这个OopMap的映射表能精确的记录当前线程在当前安全点的调用栈、寄存器等重要的数据区里是否含有引用类型的对象,这样在GC时才能精确的进行可达性分析)。如果有需要(比如需要GC时),所有线程需要在安全点挂起暂停,如果线程此刻不在安全点,那么需要继续执行到下一个安全点暂停,然后等待VM operation操作(比如GC)结束。
安全点可以安插在代码中的哪些位置?
一般JVM的实现里,安全点的选择主要考虑的是“避免程序长时间运行而不进入safepoint”,会在以下几个位置选择安全点:
- 循环的末尾
- 方法临返回前 / 调用方法的call指令后
- 可能抛异常的位置
安全点具体如何实现?
由于安全点是JVM安插到用户代码中的,因此需要了解下JVM具体是如何实现安全点放置和生效的。JVM有两种执行方式:解释型和编译型(JIT),两种执行方式下安全点实现如下:
- 解释型执行方式 JVM会设置一个2字节的dispatch tables,解释器执行的时候会经常去检查这个dispatch tables,当有safepoint请求的时候,就会让线程去进行safepoint检查(safepoint polling)。
为啥解释型执行方式只在特定位置放置安全点?引用R大的解释: 对于解释型执行方式,在解释器里每条字节码的边界都可以是一个safepoint,因为HotSpot的解释器总是能很容易的找出完整的“state of execution”。之所以只在选定的位置放置safepoint是因为:
- 挂在safepoint的调试符号信息要占用空间。如果允许每条机器码都可以是safepoint的话,需要存储的数据量会很大(当然这有办法解决,例如用delta存储和用压缩)
- safepoint会影响优化。特别是deoptimization safepoint,会迫使JVM保留一些只有解释器可能需要的、JIT编译器认定无用的变量的值。本来JIT编译器可能可以发现某些值不需要而消除它们对应的运算,如果在safepoint需要这些值的话那就只好保留了。这才是更重要的地方,所以要尽量少放置safepoint
- 像HotSpot VM这样,在safepoint会生成polling代码询问VM是否要“进入safepoint”,polling也有开销所以要尽量减少。
- JIT执行方式 JIT编译的时候直接把safepoint的检查代码加入了生成的本地代码,当JVM需要让Java线程进入safepoint的时候,只需要设置一个标志位,让Java线程运行到safepoint的时候主动检查这个标志位,如果标志被设置,那么线程停顿,如果没有被设置,那么继续执行。
例如hotspot在x86中为轮询safepoint会生成一条类似于“test %eax,0x160100”的指令,JVM需要进入gc前,先把0x160100设置为不可读,那所有线程执行到检查0x160100的test指令后都会停顿下来。
0x01b6d627: call 0x01b2b210 ; OopMap{[60]=Oop off=460}
;*invokeinterface size
; - Client1::main@113 (line 23)
; {virtual_call}
0x01b6d62c: nop ; OopMap{[60]=Oop off=461}
;*if_icmplt
; - Client1::main@118 (line 23)
0x01b6d62d: test %eax,0x160100 ; {poll}
0x01b6d633: mov 0x50(%esp),%esi
0x01b6d637: cmp %eax,%esi
JNI中的执行native代码的线程怎么处理?
JNI中,当某个线程在执行native函数的时候,此时该线程在执行JVM管理之外的代码,不能对JVM的执行状态做任何修改,因而JVM要进入safepoint不需要关心它。所以也可以把正在执行native函数的线程看作“已经进入了safepoint”,或者把这种情况叫做“在safe-region里”。JVM外部要对JVM执行状态做修改必须要通过JNI。所有能修改JVM执行状态的JNI函数在入口处都有safepoint检查,一旦JVM已经发出通知说此时应该已经到达safepoint就会在这些检查的地方停下来把控制权交给JVM。
日志样例分析
young GC日志样例(以ParNew回收器为例)
2018-11-23T18:46:17.371+0800: 934.429: [GC (Allocation Failure) 2018-11-23T18:46:17.374+0800: 934.432: [ParNew
Desired survivor size 107347968 bytes, new threshold 4 (max 4)
- age 1: 9015688 bytes, 9015688 total
- age 2: 2661984 bytes, 11677672 total
- age 3: 5833992 bytes, 17511664 total
- age 4: 2189664 bytes, 19701328 total
: 1761920K->28586K(1887488K), 0.0767716 secs] 1959490K->229493K(10276096K), 0.0802897 secs] [Times: user=0.40 sys=0.00, real=0.08 secs]
2018-11-23T18:46:17.371向Eden申请内存时失败触发了young GC, Allocation Failure表明了GC原因是分配失败导致的,如果是通过System.gc手动触发的这里会标明:System gc。
2018-11-23T18:46:17.374 young GC开始,采用ParNew回收器;期望survivor区实际占用的大小为 107347968 bytes;根据当次回收后survivor区中各年代的对象分布情况(年代信息在每个对象头里存储)重新计算提升到老年代的年代阈值为4;各年代对象在本次回收后的分布情况如上所示;本次GC后整个年轻代占用堆内存从1761920K下降到28586K(总年轻代大小为1887488K 即eden区 + 一个survivor区);整个堆的空间占用大小从1959490K下降到229493K(整个堆大小为10276096K),这里可以计算出本次GC由年轻代提升到年老代的对象大小为:(1761920K - 28586K) - (1959490K - 229493K) = 3337K。本次GC过程花了0.0802897 secs,其中使用在用户空间的时间为0.40 secs,使用在系统空间的时间为0 secs,实际真实使用的时间是0.08 secs(这里也能看出使用了并发收集器,所以用户空间的时间比实际时间要大很多,因为它是多个cpu的时间片累加的),由于Minor GC是会STW的,所以业务线程在这次GC时也暂停了80ms(这个可以从这次GC紧随着的Total time for which application threads were stopped里看出来)。
详细说一下Desired survivor size和new threshold
Desired survivor size 715816960 bytes, new threshold 3 (max 8)
- age 1: 431736800 bytes, 431736800 total
- age 2: 169874312 bytes, 601611112 total
- age 3: 176815896 bytes, 778427008 total
- age 4: 173906152 bytes, 952333160 total
: 6657093K->1386066K(6990528K), 0.1822642 secs] 11402887K->6380640K(19573440K), 0.1831642 secs] [Times: user=3.80 sys=0.06, real=0.19 secs]
”Desired survivor size“是”期望“GC后剩下的新生代的对象占用survivor空间的大小,默认是survivor的1/2的1/2(因为每次survivor区只有1/2可用),可以通过-XX:TargetSurvivorRatio来调整(默认50)。上面这个case的意思是:我希望GC后survivor区占用的空间大小为715816960 bytes,由于本次GC后 age 1 + age 2 + age 3 这3代对象占用的空间778427008已经超过了我的预期,因此重新计算新的threshold为3,这样下次GC开始时可以会把age大于等于3的对象会被直接放入老年代。这么做的原因主要是:希望留出足够的空间给从Eden区进入到survivor区的对象(默认预留的是survivor的50%)。否则GC时Eden区的对象在suvivor区放不下就会直接放入年老代,如果这时年老代也放不下就更麻烦了,这种情况会导致 promotion failed,从而触发一次“完全阻塞的CMS GC(Serial Old GC)”来快速释放年老代空间,一般都会导致比较长的业务线程停顿。
另外注意:JVM启动时设置的-XX:MaxTenuringThreshold只在第一次时强制使用,以后每次都会动态计算。
old GC日志样例(以CMS回收器为例)
2018-01-28T13:01:13.149+0800: 438741.516: [GC (CMS Initial Mark) [1 CMS-initial-mark: 6618850K(9437184K)] 7367327K(14680064K), 0.0076246 secs] [Times: user=0.03 sys=0.02, real=0.01 secs]
2018-01-28T13:01:13.157+0800: 438741.524: Total time for which application threads were stopped: 0.0197316 seconds, Stopping threads took: 0.0001682 seconds
2018-01-28T13:01:13.157+0800: 438741.524: [CMS-concurrent-mark-start]
2018-01-28T13:01:13.266+0800: 438741.633: [CMS-concurrent-mark: 0.109/0.109 secs] [Times: user=0.45 sys=0.39, real=0.11 secs]
2018-01-28T13:01:13.266+0800: 438741.633: [CMS-concurrent-preclean-start]
2018-01-28T13:01:13.292+0800: 438741.659: [CMS-concurrent-preclean: 0.025/0.026 secs] [Times: user=0.03 sys=0.02, real=0.02 secs]
2018-01-28T13:01:13.293+0800: 438741.660: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2018-01-28T13:01:18.429+0800: 438746.796: [CMS-concurrent-abortable-preclean: 5.122/5.136 secs] [Times: user=8.64 sys=9.38, real=5.14 secs]
2018-01-28T13:01:18.430+0800: 438746.797: Application time: 5.2728861 seconds
2018-01-28T13:01:18.443+0800: 438746.810: [GC (CMS Final Remark) [YG occupancy: 2128710 K (5242880 K)]2018-01-28T13:01:18.443+0800: 438746.810: [Rescan (parallel) , 0.0281534 secs]2018-01-28T13:01:18.471+0800: 438746.838: [weak refs processing, 0.0083860 secs]2018-01-28T13:01:18.480+0800: 438746.847: [class unloading, 0.0411329 secs]2018-01-28T13:01:18.521+0800: 438746.888: [scrub symbol table, 0.0093958 secs]2018-01-28T13:01:18.530+0800: 438746.897: [scrub string table, 0.0017615 secs][1 CMS-remark: 6618850K(9437184K)] 8747561K(14680064K), 0.0914312 secs] [Times: user=0.41 sys=0.26, real=0.10 secs]
2018-01-28T13:01:18.535+0800: 438746.902: Total time for which application threads were stopped: 0.1049810 seconds, Stopping threads took: 0.0005767 seconds
2018-01-28T13:01:18.535+0800: 438746.902: [CMS-concurrent-sweep-start]
2018-01-28T13:01:18.831+0800: 438747.198: [CMS-concurrent-sweep: 0.296/0.296 secs] [Times: user=0.33 sys=0.39, real=0.29 secs]
2018-01-28T13:01:18.831+0800: 438747.198: [CMS-concurrent-reset-start]
2018-01-28T13:01:18.856+0800: 438747.223: [CMS-concurrent-reset: 0.025/0.025 secs] [Times: user=0.03 sys=0.04, real=0.03 secs]
第一阶段:CMS-initial-mark(初始标记)
2018-01-28T13:01:13.149+0800: 438741.516: [GC (CMS Initial Mark) [1 CMS-initial-mark: 6618850K(9437184K)] 7367327K(14680064K), 0.0076246 secs] [Times: user=0.03 sys=0.02, real=0.01 secs]
这次old GC开始时,年老代空间占用为6618850K(总共年老代空间为9437184K),整个年轻代+年老代的已占用空间为7367327K,整个年轻代和年老代总大小为14680064K,本阶段花费的用户空间耗时30ms,系统空间耗时20ms,实际墙钟耗时10ms,这个阶段在jdk 1.8之前是单线程执行的,jdk 1.8里是多线程并行执行的,但是暂停业务线程的。 这个阶段主要做两件事:
- 遍历年老代中GC Roots可以 直接 到达的对象(这些对象还有引用不能回收)。
- 遍历被新生代存活对象所引用的老年代对象。
PS: 分代回收机制下,在执行部分收集时,从GC堆的非收集部分指向收集部分的引用,也必须作为GC Roots的一部分,所以old GC时年轻代也需要作为年老代的GC Roots,所以这里也需要遍历年轻代。但一般情况下,初始标记阶段是由于young GC刚完成有对象promote到年老代后使得年老代达到old GC触发的阈值后发生的,所以这个时候一般年轻代刚GC完占用比较小,所以也不会太慢。但特殊情况下如果碰巧年轻代比较大,初始标记阶段耗时就会比较长。JVM提供了一个参数–XX:CMSWaitDuration来配置初始标记阶段可以等待多长时间来等一次young GC的发生。
第二阶段:concurrent-mark(并发标记)
2018-01-28T13:01:13.157+0800: 438741.524: [CMS-concurrent-mark-start]
2018-01-28T13:01:13.266+0800: 438741.633: [CMS-concurrent-mark: 0.109/0.109 secs] [Times: user=0.45 sys=0.39, real=0.11 secs]
整个阶段花费的用户空间耗时为450ms,系统空间耗时为390ms,实际墙钟耗时是110ms,这个阶段是和业务线程并发执行的,不会STW。 这个阶段主要做两件事:
- 对第一阶段标记出的对象进一步进行递归标记(被引用的对象也不能回收)。
- 记录自身执行期间发生了引用变化或者晋升变化的对象。
知识点:如何记录并发标记期间发生的变化?
三色标记 并发执行阶段发生引用变化或者晋升变化的情况很多,比如:
- 执行期间有对象从年轻代晋升到年老代或者有对象直接在年老代分配对象。
- 年老代中对象引用发生变化。
- 年轻代中原本引用年老代对象的解除了引用或者年轻代中原本没引用年老代的新增了对年老代对象的引用。
- 等等。
为了解决并发标记阶段由于引用发生变化导致对象“漏标”的问题,JVM将对象分为3类:black对象、grey对象、white对象。
- white对象:未被扫描对象,扫描完成所有对象之后,最终为白色的为不可达对象,即垃圾对象
- grey对象:自身已经被标记到,但其所有引用字段还没有处理的对象;
- black对象:自身已经被标记到,且其引用的所有对象也已经被标记的对象。
一个white对象在并发标记阶段会被漏标的充分必要条件是:
1. 应用程序(mutator)插入了一个从black对象到该white对象的新引用。
2. 应用程序(mutator)删除了所有从grey对象到该white对象的直接或者间接引用。
如下情况:
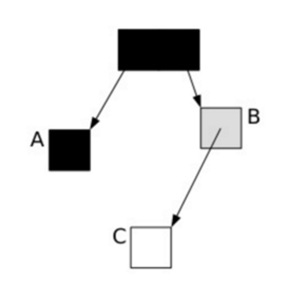
对象A已经完成了标记(记为black),对象B本身完成标记、但子对象还没标记(记为grey),对象C还没有标记。mutator(应用程序)这时进行了以下赋值操作:
```
A.c=C
B.c=null
```
这样对象的引用关系变成了:
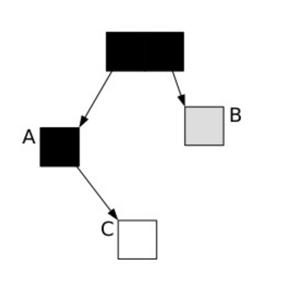
导致垃圾回收器继续扫描时会导致“本不该被回收的C对象被标记为white对象而被错误的回收掉”。
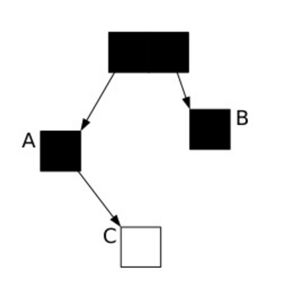
问题:并发标记阶段如何保证mutator(应用程序)运行过程中由于赋值操作变化导致对象被“漏标记”而被错误回收?
JVM有两种可行方式来实现:
-
- 在插入新的引用时候记录变化对象
-
- 在解除引用关系的时候记录变化对象
1. CMS的实现方式(Incremental update)
CMS的并发标记采用的是第一种:Incremental update(增量更新),简单描述就是:当发现有一个white对象的引用被赋值到一个black对象的字段里,那就把这个白对象变成灰色的。即插入的时候记录下来。
具体实现细节: JVM提供了两种数据结构来对增量GC的并发标记过程中发生变化的对象进行记录,第一种是Card Table;第二种是Mod Union Table。
-
CardTable介绍 为了提升垃圾回收效率,JVM将内存分成一个个固定大小的Card(一般4K),通过一个专门的数据结构Card Table来维护每个Card的状态(其实就是单字节的数组),一个字节对应一个Card,当一个Card上的引用发生变化时,JVM会将这个Card对应的Card Table标记为dirty(标记在引用变化的出发端point-out),具体实现是JVM在对象引用赋值的指令集插入一个post write barrier,暂时中断来更新Card Table。
-
CardTable作用
-
比如Young GC时,由于年老代中指向年轻代的这些对象也需要作为GC Roots来进行标记,因此就可以通过扫描这个Card Table知道上一次Young GC后哪些年老代对象发生了引用变化,只需要扫描这些变化的Card的对象即可,不需要扫描整个年老代了。
-
同样old GC(比如CMS)也会通过Card Table记录在并发标记期间所有年老代中发生了引用关系变化的Card,后面在pre clean阶段就只需要不断扫描这个Card Table就能避免扫描整个年老代的工作量了。
- Mod Union Table介绍 实际上Card Table并不区分发生引用变化的对象所属的年代,而是记录所有发生了变化的引用的出发端,无论在old还是young。所以如果在并发标记期间发生了Young GC,Young GC时扫描Card Table中从年老代到年轻代引用发生了变化的这些年老代对象,如果某个Card没有到年轻代的引用了,那么Young GC会把这个Card从Dirty标记为Clean,由于并发标记阶段是可以和Young GC并发执行的,这样可能会把在并发标记期间old GC已经标记为Dirty的Card(比如这个Card在并发标记期间引用其他年老代对象发生了变化)重置成Clean了,这样就会出现对象“漏标”的情况,导致不该被回收的对象被回收了。为了解决这个问题,JVM在old GC还提供了一个Mod Union Table的BitMap的结构(一个bit对应一个Card),在并发标记阶段,如果发生Young GC需要将某些年老代Card对应的CardTable重置的时候,就会更新Mod Union Table里这个Card对应的Bit为dirty状态。这样在后续处理阶段可以通过遍历Card Table和Mod Union Table那些dirty的Card来获取并发阶段年老代所有的引用变化了。
2. G1的实现方式(SATB Snapshot-At-The-Beginning)
Incremental update的实现是通过“打破第一个条件(引用关系的插入)”来保证不“漏标”,而SATB是通过“打破第二个条件(引用关系的删除)来”实现的。SATB利用pre write barrier将所有即将被删除的引用关系的旧引用记录下来,最后以这些旧引用为根STW地重新扫描一遍即可避免漏标问题。
G1并发标记过程使用SATB的步骤:
- 由于G1采用的是"复制"算法,所以每一个region里的内存都是整齐的,并发标记阶段开始时记录下当前region分配位置的指针TAMS(top-at-mark-start),并发标记过程中在此指针后分配的对象都被标记为"隐式已标记对象",所以这些新对象都能活过这一次GC。
- 并发标记过程中在mutator并发覆盖某些字段引用值的时候通过pre write barrier在覆盖前记录旧的引用对象到一个satb_mark_queue的队列(每个java线程一个队列),在下一轮并发标记或者最终标记的时候会去检查并处理这个队列的对象进行递归标记,通过这种方式实现了类似"并发标记开始时快照"的效果。
G1的concurrent marking用了两个bitmap:
一个prevBitmap记录第n-1轮concurrent marking所得的对象存活状态。由于第n-1轮concurrent marking已经完成,这个bitmap的信息可以直接使用。
一个nextBitmap记录第n轮concurrent marking的结果。这个bitmap是当前将要或正在进行的concurrent marking的结果,尚未完成,所以还不能使用。
对应的,每个region都有这么几个指针:
|<-- (1) -->|<-- (2) -->|<-- (3) -->|<-- (4) -->|
bottom prevTAMS nextTAMS top end
>其中top是该region的当前分配指针,[bottom, top)是当前该region已用(used)的部分,[top, end)是尚未使用的可分配空间(unused)。
(1): [bottom, prevTAMS): 这部分里的对象存活信息可以通过prevBitmap来得知
(2): [prevTAMS, nextTAMS): 这部分里的对象在第n-1轮concurrent marking是隐式存活的
(3): [nextTAMS, top): 这部分里的对象在第n轮concurrent marking是隐式存活的
思考:Incremental update和SATB存在的一些问题?
- 浮动垃圾(floating garbage) 不管是Incremental update还是SATB,关注点还是在“保证不被漏标”,而不是“保证不被错标”,因此会存在“原本应该被回收的对象没有被回收掉”的浮动垃圾问题。如Incremental update导致浮动垃圾的一些情况:
- 在CMS的整个收集过程中,创建出来的新对象都是black对象,这种情况OK的,最多只是造成了本来可以被GC的对象在这一次不会被回收(floating garbage)。
- 由于CMS的write barrier是Incremental update,只会将并发阶段所有新插入的引用记录下来,而不会记录引用的删除,因此如果并发阶段有原来已标记的对象被解除了引用,也不会在这次被回收。这种也属于floating garbage。
知识点: 既然Card Table记录了堆中所有引用的变化,为啥old GC的init-mark和remark阶段还需要扫描整个年轻代作为GC Roots而不从Card Table来获取?这里引用一下R大的解释:
但是HotSpot VM只使用了old gen部分的card table,也就是说只关心old -> ?的引用。这是因为一般认为young gen的引用变化率(mutation rate)非常高,其对应的card table部分可能大部分都是dirty的,要把young gen当作root的时候与其扫描card table还不如直接扫描整个young gen。
对于CMS GC来说,remark阶段由于以下原因需要重新扫描young区和所有GC ROOTS:
- 由于young区变化太快,重新扫描card table里的记录的变更和整体重新扫一遍young区没区别。
- 由于CMS采用的是post write barrier,只记录变更后的新插入引用,而且类似"给局部变量赋值"的astore指令并没有write barrier,会存在栈上对象漏标的情况,因此还需要遍历整个GC ROOTS。
对于G1的remark阶段为什么不需要遍历young区和GC ROOTS,也不用遍历所有old regions的原因:
- 由于G1采用的SATB的快照方式来记录并发标记期间的所有引用覆盖行为,因此并发过程中不会出现"灰对象删除对白对象的引用后导致白对象可能被漏标"的情况。
- G1采用TAMS指针保证并发期间所有新产生的对象都会被标记到。
- 通过remember set来记录哪些region引用到了本region,只需要扫描这些region里的card table,避免遍历所有region。YGC时只需要选取young regions的RSet作为根集进行遍历;Mixed GC时也只需要选择CSet(Collection Set 被选取回收的regions)里的regions的RSet作为根集进行遍历。
"Points-into" remembered set
G1 GC的heap与HotSpot VM的其它GC一样有一个覆盖整个heap的card table。
逻辑上说,G1 GC的remembered set(下面简称RSet)是每个region有一份。这个RSet记录的是从别的region指向该region的card。所以这是一种“points-into”的remembered set。
用card table实现的remembered set通常是points-out的,也就是说card table要记录的是从它覆盖的范围出发指向别的范围的指针。以分代式GC的card table为例,要记录old -> young的跨代指针,被标记的card是old gen范围内的。
G1 GC则是在points-out的card table之上再加了一层结构来构成points-into RSet:每个region会记录下到底哪些别的region有指向自己的指针,而这些指针分别在哪些card的范围内。
这个RSet其实是一个hash table,key是别的region的起始地址,value是一个集合,里面的元素是card table的index。
举例来说,如果region A的RSet里有一项的key是region B,value里有index为1234的card,它的意思就是region B的一个card里有引用指向region A。所以对region A来说,该RSet记录的是points-into的关系;而card table仍然记录了points-out的关系。
- 第三阶段:concurrent-preclean(并发预清理)
2018-01-28T13:01:13.266+0800: 438741.633: [CMS-concurrent-preclean-start]
2018-01-28T13:01:13.292+0800: 438741.659: [CMS-concurrent-preclean: 0.025/0.026 secs] [Times: user=0.03 sys=0.02, real=0.02 secs]
并发预清理阶段可以通过JVM参数CMSPrecleaningEnabled来控制不执行(默认执行),该阶段也是和业务线程一起并发执行的。主要做的事情有:
- 标记上一个阶段年老代新增的对象引用,比如并发标记期间在eden区新分配的对象引用了年老代之前没被标记过的对象,这时需要标记这个年老代对象。
- 扫描并发标记阶段年老代中由于引用发生变化的Card Table和Mod Union Card对应的Card,重新进行标记。
这个阶段的目的是尽量降低后面会STW的Remark阶段的工作量。
- 第四阶段:concurrent-abortable-preclean(并发可取消的预清理)
2018-01-28T13:01:13.293+0800: 438741.660: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 2018-01-28T13:01:18.429+0800: 438746.796: [CMS-concurrent-abortable-preclean: 5.122/5.136 secs] [Times: user=8.64 sys=9.38, real=5.14 secs]
该阶段只有在新生代的eden区使用量大于2M(CMSScheduleRemarkEdenSizeThreshold参数控制,默认2M)时才会执行,如果新生代对象太少就跳过该阶段直接进行重新标记阶段。这个阶段主要循环的做上一个阶段的工作。
这个阶段存在的意义有两个:
- 尽最大努力处理并发阶段被应用线程更新的老年代对象,这样在下一个STW的重标记阶段就能耗时更短一些。
- 等待一次Minor GC的发生,这样后面Remark阶段扫描整个年轻代时工作量会小很多,这也是这个阶段只有在新生代比较大的时候才触发的原因。
循环终止的条件有3个:
- 可以设置最多循环的次数(CMSMaxAbortablePrecleanLoops参数控制),默认无限。
- 执行时间达到一定阈值(CMSMaxAbortablePrecleanTime参数控制),默认5s。
- 新生代eden区内存使用率达到阈值(CMSScheduleRemarkEdenPenetration参数控制,默认50%),还有一个前提是进行开始preclean时eden区使用率小于1/10。
上面例子这次preclean墙钟耗时5.14s,中止的原因就是由于达到执行时间阈值了(abort preclean due to time)。
- 第五阶段:Final Remark(最终重标记)
2018-01-28T13:01:18.443+0800: 438746.810: [GC (CMS Final Remark) [YG occupancy: 2128710 K (5242880 K)]2018-01-28T13:01:18.443+0800: 438746.810: [Rescan (parallel) , 0.0281534 secs]2018-01-28T13:01:18.471+0800: 438746.838: [weak refs processing, 0.0083860 secs]2018-01-28T13:01:18.480+0800: 438746.847: [class unloading, 0.0411329 secs]2018-01-28T13:01:18.521+0800: 438746.888: [scrub symbol table, 0.0093958 secs]2018-01-28T13:01:18.530+0800: 438746.897: [scrub string table, 0.0017615 secs][1 CMS-remark: 6618850K(9437184K)] 8747561K(14680064K), 0.0914312 secs] [Times: user=0.41 sys=0.26, real=0.10 secs]
2018-01-28T13:01:18.535+0800: 438746.902: Total time for which application threads were stopped: 0.1049810 seconds, Stopping threads took: 0.0005767 seconds
重标记阶段是多线程并行执行的,也是STW的,主要做的事情有:
- 遍历新生代对象,重新标记到年老代有引用的年老代对象。
- 根据GC ROOTs重新标记那些年老代中新增的被GC ROOTS引用的对象。
- 遍历年老代的并发标记阶段发生引用变更的Dirty Card和Mod Union Card进行重新标记。
知识点: 遍历新生代和GC Roots的原因:
前面提到一个white对象在并发标记阶段会被漏标的充分必要条件是: 1. 业务线程(mutator)插入了一个从black对象到该white对象的新引用。 2. 业务线程(mutator)删除了所有从grey对象到该white对象的直接或者间接引用。 CMS允许在被初始标记之后到并发标记结束前,black对象还可以继续引用white对象(比如方法中新的局部变量赋值给灰对象指向的白对象,然后灰对象删除了对这个白对象的引用,见下面代码示例),这样会造成这个白对象被漏标。因此remark解析需要重新遍历新生代和GC Roots,同时遍历Card Table和Mod Union Table来完成最终的标记。但这里由于Initial Mark和concurrent Mark两个阶段已经把绝大部分对象标记完了,所以每个GC Roots扫描的时候碰到已经标记完成的black的对象就会终止,所以递归标记的时间并不会太长。
public static void main(String[] args) {
Animal p = new Dog();
p.child = new Dog();
p.child.bark();
Animal q = p.child;
p.child = null;
q.bark();
}
假设第4行代码执行完毕后CMS开始,initial mark将local1指向的Dog对象标记,然后concurrent mark开始,假设main“先”执行,“Animal q = p.child”使得local2(即局部变量q)指向p.child,但由于这个引用关系是通过astore_2字节码添加的,该字节码没有write barrier(能引发write barrier的字节码只有putfield,putstatic和aastore),且p.child这个操作对应的字节码getfiled也没有read barrier,因此刚添加的这个从q到p.child的引用并不会被card table或者mod-union table记录下来,然后执行“p.child = null”使得灰对象p到白对象p.child的引用关系被删除了,但由于是incremental update而非SATB,引用关系的删除也没有记录。 因此,remark阶段必须重新扫描root,否则q到p.child的引用关系就丢失了。
参考上面的示例,两个值得注意的点:
- JVM在stack区域并不会使用write barrier记录引用的变化。
- 年轻代虽然会通过Card Table记录年轻代到年老代的变化但Remark阶段并不会使用它。 可能的原因是stack和年轻代都属于数据快速变化区,这样这两个区的大部分区域在并发标记阶段都会被write barrier记录下来,最终也减少不了多少扫描的区域,所以还不如Remark的时候整体再扫描一遍。
由于这个阶段需要遍历新生代对象,如果新生代对象比较多的话,这个阶段耗时会比较高,如果刚好在abortable-preclean阶段发生了一次Minor GC这样能避免扫描无用对象,效率会高很多。因此JVM提供了一个参数(CMSScavengeBeforeRemark)在执行Final Remark前强制触发一次Minor GC(默认不开启),这样可以降低Final Remark阶段的停顿时间,但也会多一次Minor GC的开销(如过年轻代刚GC过的话)。
上例中: YG occupancy: 2128710 K (5242880 K):此时年轻代使用2128710 K Rescan (parallel) , 0.0281534 secs: 并行的重新扫描花了28ms weak refs processing, 0.0083860 secs: 弱引用处理花了8ms (weak refs processing主要包括SoftReference、WeakReference、FinalReference、PhantomReference以及JNI Weak Reference这五种Reference对象的处理) class unloading, 0.0411329 secs: 卸载不用的类花了4ms scrub symbol table, 0.0093958 secs: 清理metadata的符号表花了9ms scrub string table, 0.0017615 secs: 清理内部化字符串对应的string tables花了1.7ms CMS-remark: 6618850K(9437184K)] 8747561K(14680064K): 完成后老年代占用6618850K,整个堆占用8747561K。 Times: user=0.41 sys=0.26, real=0.10 secs: 整个墙钟耗时100ms
知识点: 有的时候如果发现弱引用处理花费时间太长,可以通过-XX:+PrintReferenceGC来打印各种待处理的引用的数量,如果确认是由于数量太多导致的处理慢,可以通过-XX:+ParallelRefProcEnabled来并行处理引用(并行处理的线程数由ParallelGCThreads控制,引用处理默认是单线程处理)。
- 第六阶段:concurrent-sweep(并发清除)
2018-01-28T13:01:18.535+0800: 438746.902: [CMS-concurrent-sweep-start]
2018-01-28T13:01:18.831+0800: 438747.198: [CMS-concurrent-sweep: 0.296/0.296 secs] [Times: user=0.33 sys=0.39, real=0.29 secs]
这个阶段主要是对没有被标记的垃圾对象进行并发清理,真正的清理回收内存,也就是将“没有被标记的对象”占用的内存还回到freelist,过程中如果碰到回收多个连续内存块时还会做一些合并工作(一定程度上缓解了CMS的碎片化问题)。这个阶段是和业务线程并发执行的,执行的时候会hold住freelistLock,保证执行过程中不会有新的对象会被分配在老年代里,这样年轻代GC其实这时是也是无法执行的(无法向老年代promote)。
Q&A:并发清除阶段是可以和应用并发执行的,如果在这个阶段发生新的对象引用变化,如何保证不发生"错误回收"? 1. 由于remark阶段已经完成了整个老年代所有对象"存活"与否的判断,在这个阶段不可能存在"死对象被重新引用复活"的情况,因为"死对象"肯定代码里已经无法触达了。 2. 在整个CMS的收集阶段所有新创建的对象都是黑色的,因此能保证此轮GC这些新对象都能存活。(貌似Hotspot的实现是通过freelistLock来保证这个阶段老年代不会发生对象分配。)
void CMSCollector::sweepWork(ConcurrentMarkSweepGeneration* gen,
bool asynch) {
// We iterate over the space(s) underlying this generation,
// checking the mark bit map to see if the bits corresponding
// to specific blocks are marked or not. Blocks that are
// marked are live and are not swept up. All remaining blocks
// are swept up, with coalescing on-the-fly as we sweep up
// contiguous free and/or garbage blocks:
// We need to ensure that the sweeper synchronizes with allocators
// and stop-the-world collectors. In particular, the following
// locks are used:
// . CMS token: if this is held, a stop the world collection cannot occur
// . freelistLock: if this is held no allocation can occur from this
// generation by another thread
// . bitMapLock: if this is held, no other thread can access or update
//
// Note that we need to hold the freelistLock if we use
// block iterate below; else the iterator might go awry if
// a mutator (or promotion) causes block contents to change
// (for instance if the allocator divvies up a block).
// If we hold the free list lock, for all practical purposes
// young generation GC's can't occur (they'll usually need to
// promote), so we might as well prevent all young generation
// GC's while we do a sweeping step. For the same reason, we might
// as well take the bit map lock for the entire duration
- 第七阶段 concurrent-reset (并发重置)
2018-01-28T13:01:18.831+0800: 438747.198: [CMS-concurrent-reset-start]
2018-01-28T13:01:18.856+0800: 438747.223: [CMS-concurrent-reset: 0.025/0.025 secs] [Times: user=0.03 sys=0.04, real=0.03 secs]
这个阶段也是和业务线程并发执行的,主要是重置CMS算法相关的内部数据,为下一次GC做准备。
参考:
现代JVM中的Safe Region和Safe Point到底是如何定义和划分的? 理解JVM的safepoint 图解CMS垃圾回收机制 并发垃圾收集器(CMS)为什么没有采用标记-整理算法来实现? G1详解 请教G1算法的原理 关于CMS、G1垃圾回收器的重新标记、最终标记疑惑? 关于incremental update与SATB的一点理解